The first virtual CVPR conference ended, with 1467 papers accepted, 29 tutorials, 64 workshops, and 7.6k virtual attendees. The huge number of papers and the new virtual version made navigating the conference overwhelming (and very slow) at times. To get a grasp of the general trends of the conference this year, I will present in this blog post a sort of a snapshot of the conference by summarizing some papers (& listing some) that grabbed my attention.
- All of the papers can be found here: CVPR2020 open access
- CVPR virtual website: CVPR2020 virtual
Disclaimer: This post is not a representation of the papers and subjects presented in CVPR; it is just a personnel overview of what I found interesting. Any feedback is welcomed!
- CVPR 2020 in numbers
- Recognition, Detection and Segmentation
- Generative models and image synthesis
- Representation Learning
- Computational photography
- Transfer/Low-shot/Semi/Unsupervised Learning
- Vision and Language
- The rest
CVPR 2020 in numbers
The statistics presented in this section are taken from the official Opening & Awards presentation. Let’s start by some general statistics:
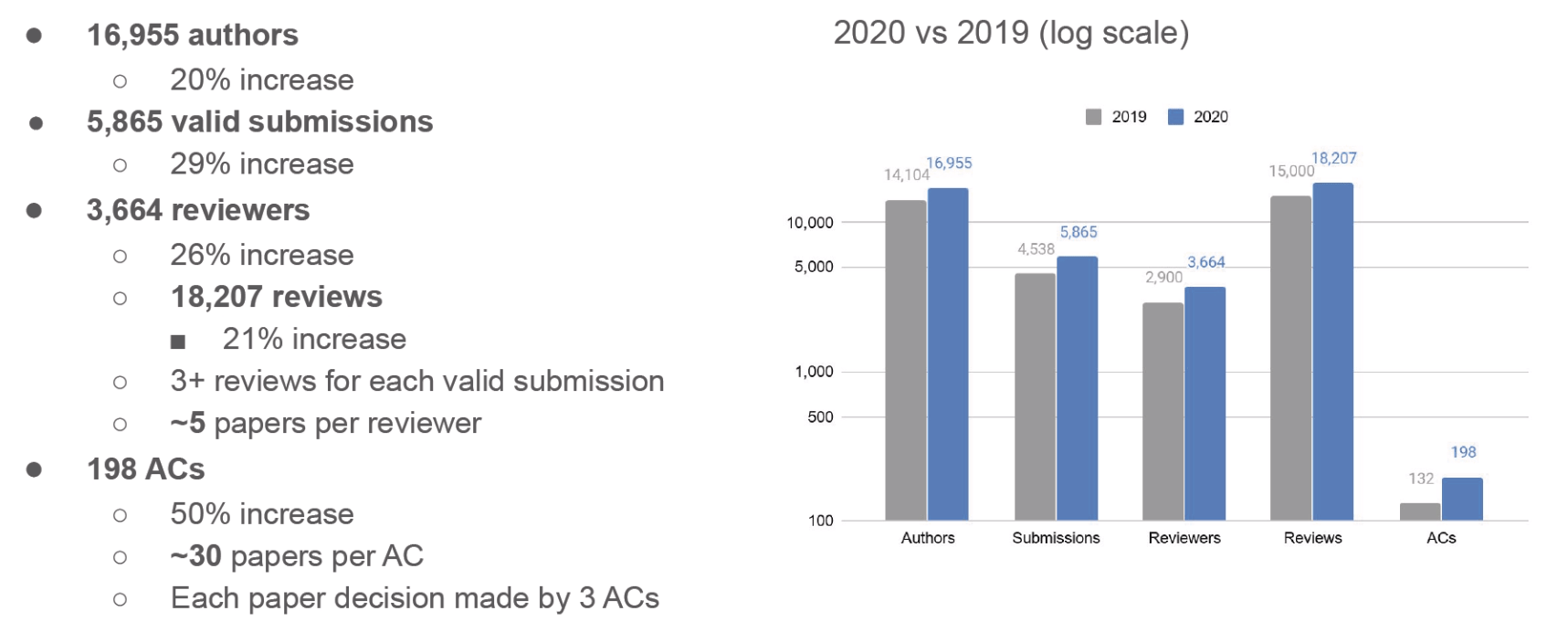
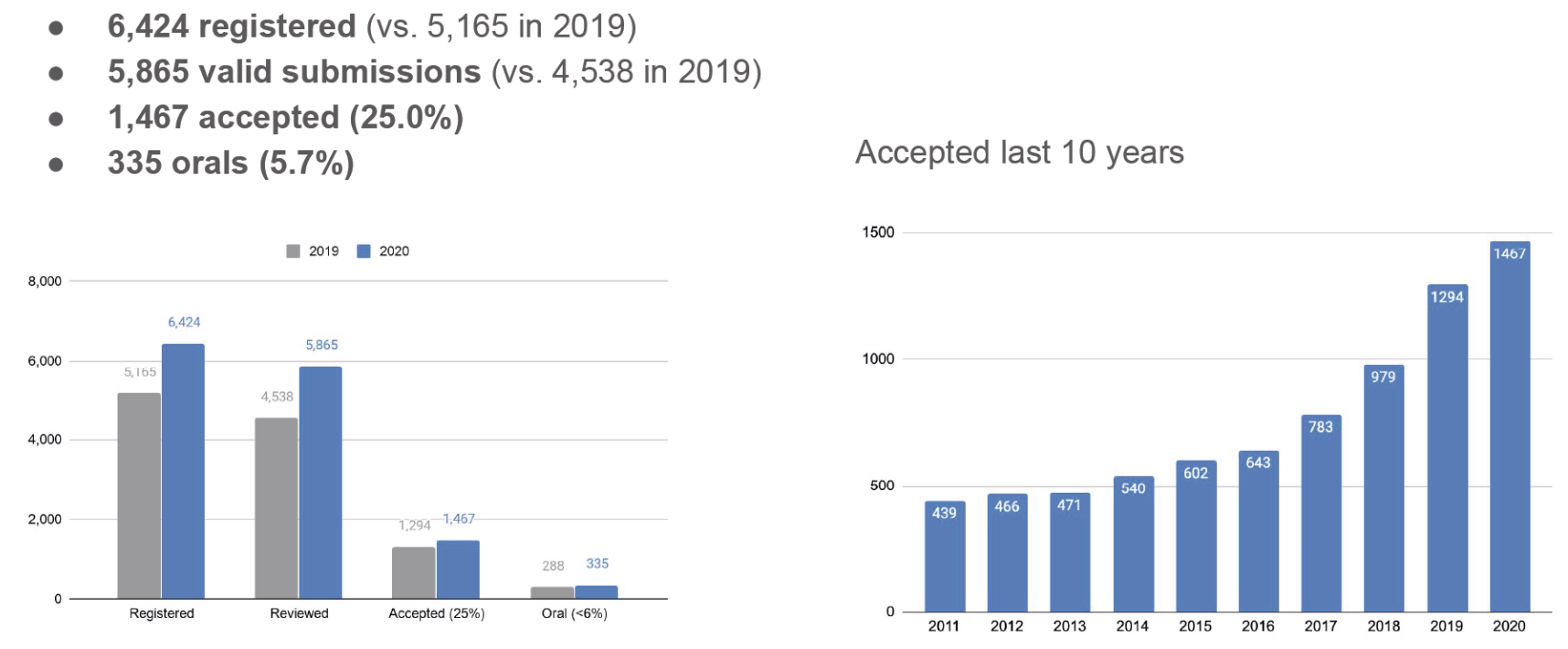
The trends of earlier years continued with a 20% increase in authors and a 29% increase in submitted papers, joined by rising the number of reviewers and area chairs to accommodate this expansion.
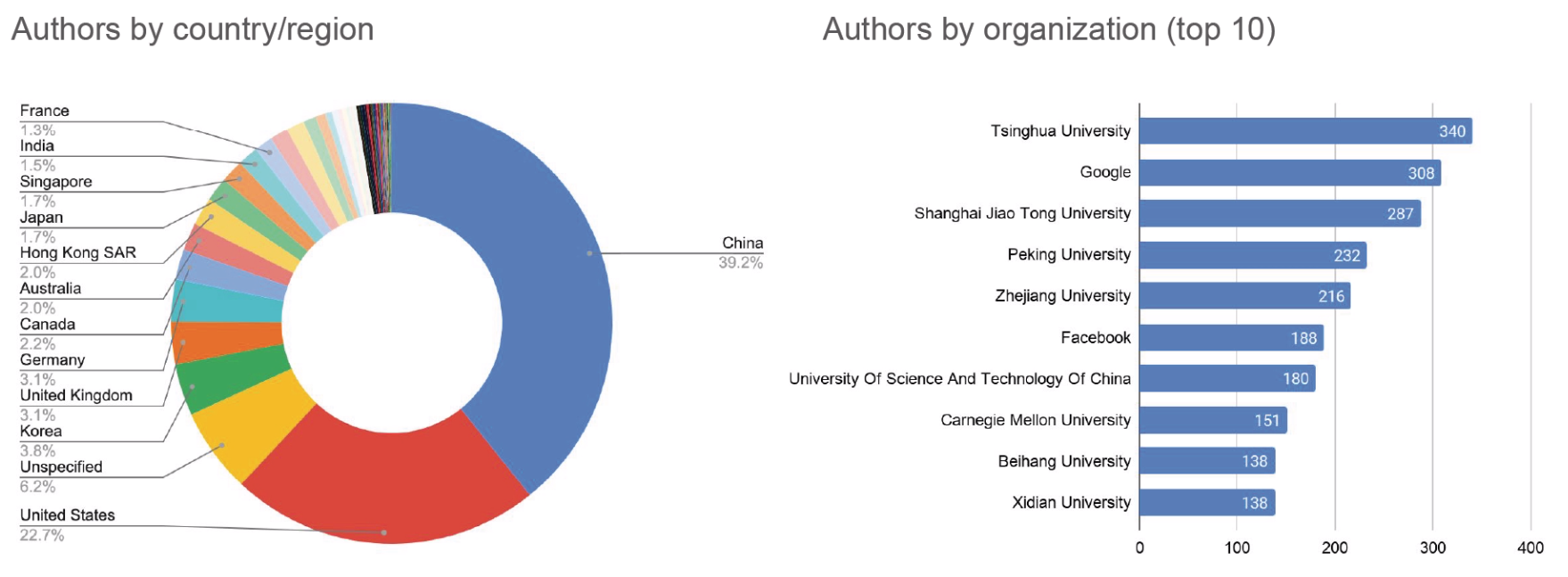
Similar to last year, China is the first contributor to CVPR in terms of accepted papers with Tsinghua University with the most significant number of authors, followed by the USA as the second contributor by country and Google by organization.
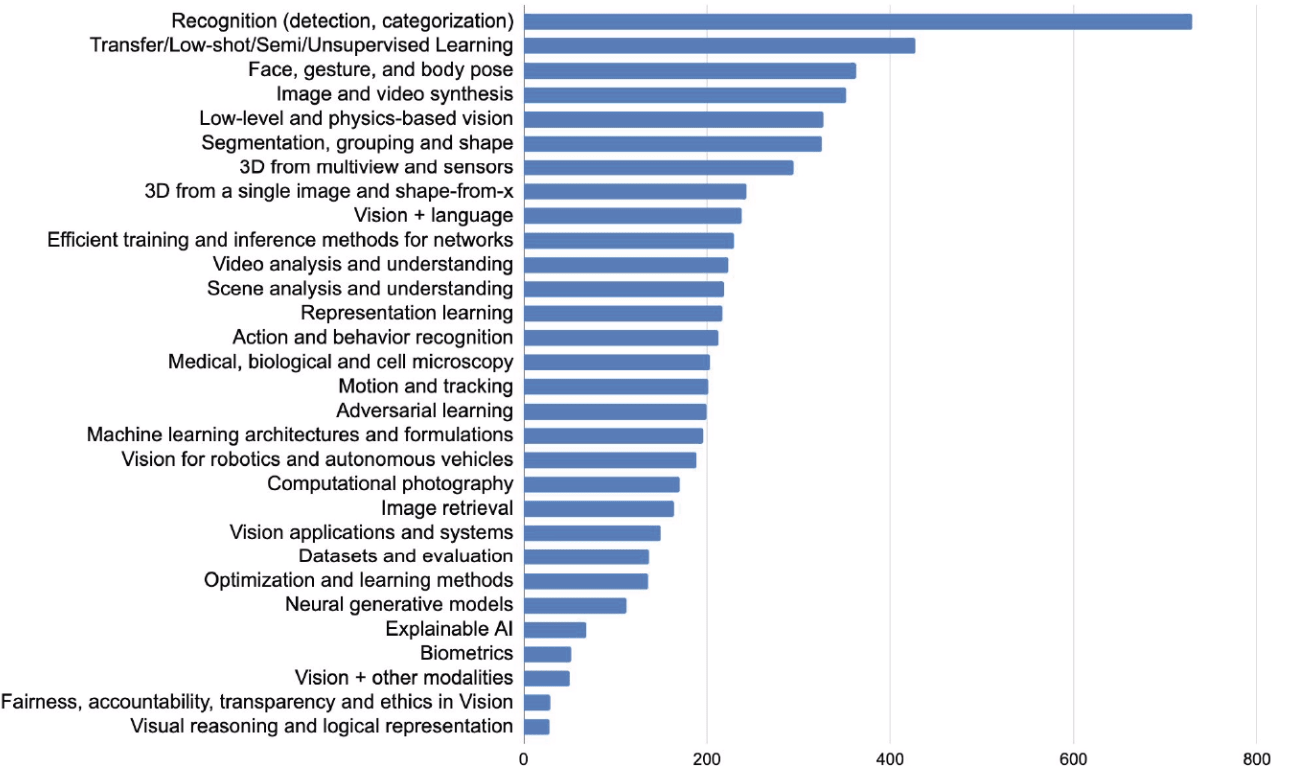
As expected, the majority of the accepted papers focus on topics related to learning, recognition, detection, and understanding. However, there is an increasing interest in relatively new areas such as label-efficient methods (e.g., transfer learning), image synthesis and robotic perception. Some emerging topics like fairness and explain AI are also starting to gather more attention within the computer vision community.
Recognition, Detection and Segmentation
PointRend: Image segmentation as rendering (paper)
Image segmentation models, such as Mask R-CNN, typically operate on regular grids: the input image is a regular grid of pixels, their hidden representations are feature vectors on a regular grid, and their outputs are label maps on a regular grid. However, a regular grid will unnecessarily over sample the smooth areas while simultaneously undersampling object boundaries, often resulting in blurry contours, as illustrated in the right figure below.
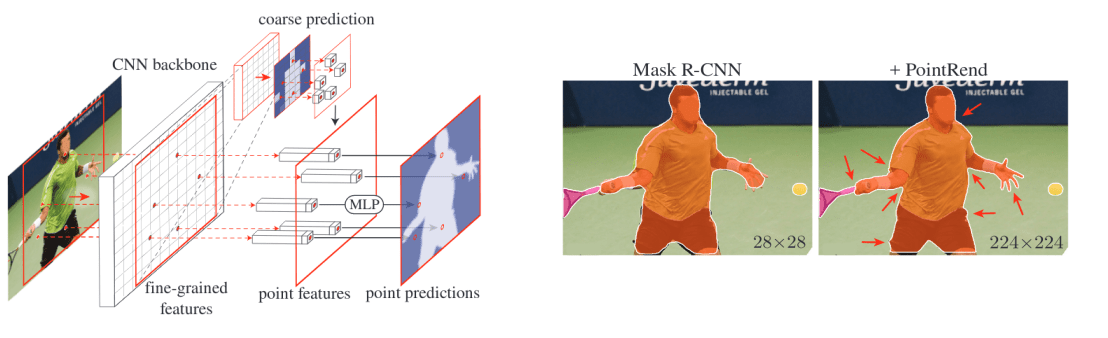
The paper proposes to view image segmentation as a rendering problem and adapt classical ideas from computer graphics to render high-quality label maps efficiently. This is done using a neural network module called PointRend. PointRend takes as input a given number of CNN feature maps that are defined over regular grids and outputs high-resolution predictions over a finer grid. These fine predictions are only made in carefully selected points, chosen to be near high-frequency areas such as object boundaries where we have uncertain predictions (i.e., similar to adaptive subdivision), which are then upsampled and a small subhead is used to make the prediction from such point-wise features.
Self-training with Noisy Student improves ImageNet classification (paper)
Semi-supervised learning methods work quite well in a low-data regime, but with a large number of labeled data, fully-supervised learning still works best. In this paper, the authors revisit this assumption and show that noisy self-training works well, even when labeled data is abundant.
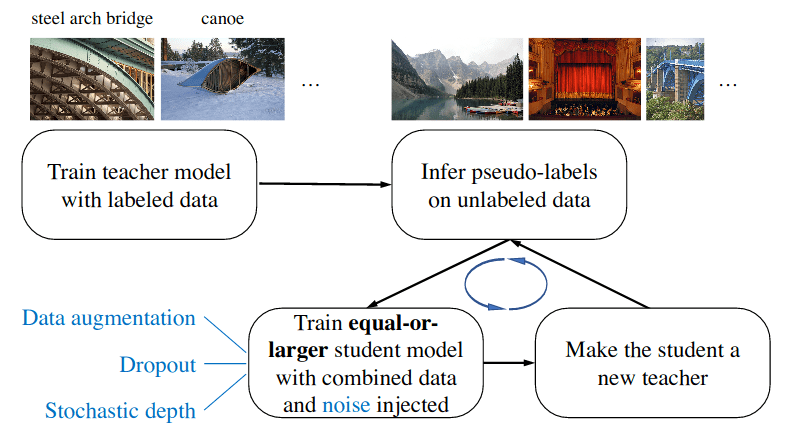
The method used a large corpus of unlabeled images (i.e., different than ImageNet training set distribution), and consists of three main steps. First, a teacher model is trained on the labeled images, the trained teacher is then used to generate pseudo-labels on the unlabeled images, which are then used to train a student model on the combination of labeled images and pseudo-labeled images, the student model is larger than the teacher (e.g., starting with EfficientNetB0 then EfficientNetB3) and is trained with an injected noise (e.g., dropout). The student is then considered as a teacher, and the last two-step are repeated a few times to relabel the unlabeled data and training a new student. The last model achieves SOTA on ImageNet top-1 and shows a higher degree of robustness.
Designing network design spaces (paper)
Instead of focusing on designing individual network instances, this paper focuses on designing network design spaces that parametrize populations of networks, in order to find some guiding design principals for fast and simple networks.
The proposed method focuses on finding a good model population instead of good model instances (e.g., natural architecture search). Based on the comparison paradigm of distribution estimates, the process consists of initializing a design space A, followed by introducing a new design principle to obtain a new and refined design space B, containing simpler and better models. The process is repeated until the resulting population consists of models that are more likely to be robust and generalize well.
EfficientDet: Scalable and Efficient Object Detection (paper)
EfficientDet is a model with STOA in object detection, with better efficiency across a wide range of resource constraints.
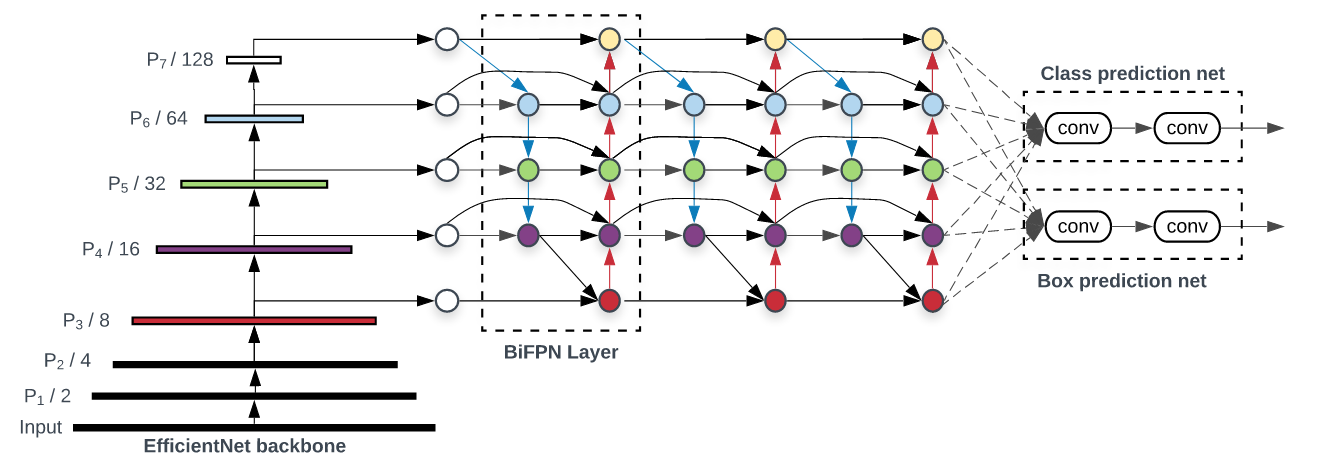
The model’s architecture with an EfficientNet backbone consists of two new design choices: a bidirectional Feature Pyramid Network (FPN) with a bidirectional topology, or BiFPN, and using learned weights when merging the features from different scales. Additionally, the network is designed with compound scaling, where the backbone, class/box network and input resolution are jointly adapted to meet a wide spectrum of resource constraints, instead of simply employing bigger backbone networks as done in previous works.
Dynamic Convolution: Attention Over Convolution Kernels (paper)
One of the main problems with light-weight CNNs, such as MobileNetV2, is their limited representation capability due to the constrained depth (i.e., number of layers) and width (i.e., number of channels) to maintain low computational requirements. In this paper, the authors propose dynamic convolutions to boost the capability of the convolution layers by aggregating the results of multiple parallel convolutions with attention weights, without increasing the computation significantly.
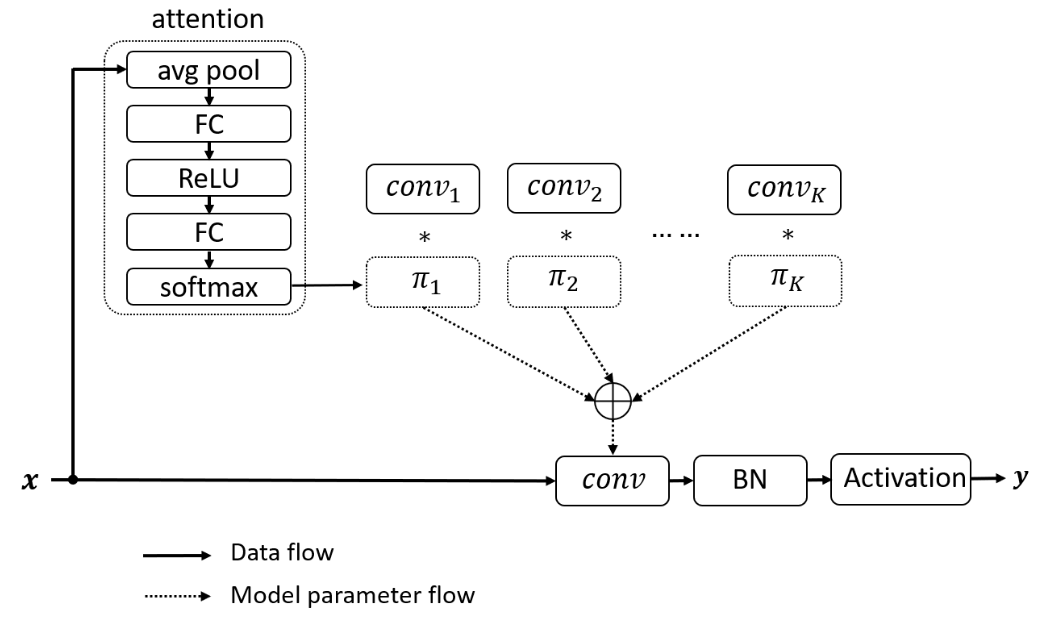
Dynamic convolutions consist of applying K convolution kernels that share the same kernel size and input/output dimensions instead of a single operation, their results are then aggregated using attention weights produced with small attention module. For faster training, the kernel weights are constrained to triangles where each attention weights are in range [0, 1] and their sum equal to one.
PolarMask: Single Shot Instance Segmentation with Polar Representation (paper)
PolarMask proposes to represent the masks for each detected object in an instance segmentation task using polar coordinates. Polar representation compared to Cartesian representation has many inherent advantages: (1) The origin point of the Polar coordinates can be seen as the center of the object. (2) Starting from the origin point, the contour of the object can be determined only by the distance from the center and the angle. (3) The angle is naturally directional (starting from 0° to 360°) and makes it very convenient to connect the points into a whole contour.
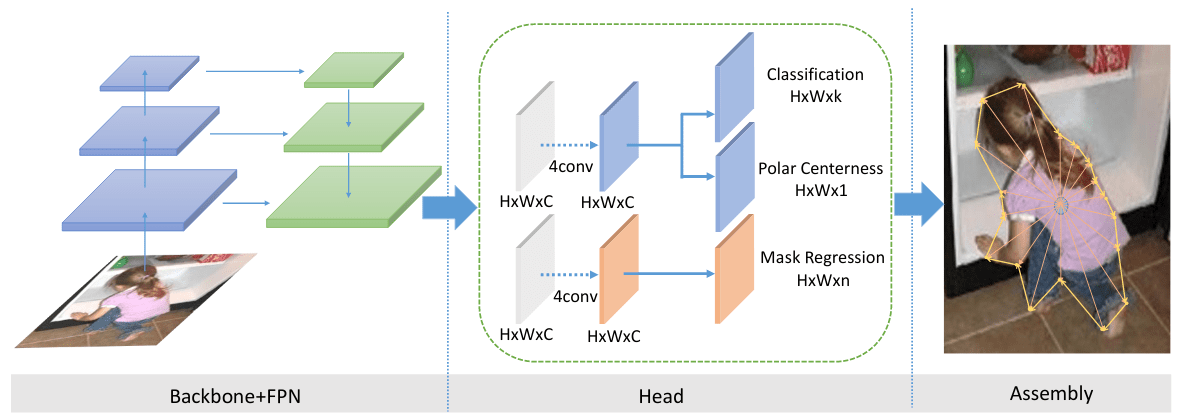
The model is based on FCOS, where for a given instance, we have three outputs: the classification probabilities over \(k\) classes (e.g., \(k= 80\) on COCO dataset), the center of the object (Polar Centerness), and the distances from the center (Mask Regression). The paper proposes to use \(n = 36\) distances from the center, so the angle between two points in the contour is 10° in this case. Based on these outputs, the extent of each object can be detected easily in a single shot manner without needing a sub-head network for pixel-wise segmentation over each detected object as in Mask-RCNN.
Other papers:
- Deep Snake for Real-Time Instance Segmentation
- Exploring Self-attention for Image Recognition
- Bridging the Gap Between Anchor-based and Anchor-free Detection
- SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
- Look-into-Object: Self-supervised Structure Modeling for Object Recognition
- Learning to Cluster Faces via Confidence and Connectivity Estimation
- PADS: Policy-Adapted Sampling for Visual Similarity Learning
- Evaluating Weakly Supervised Object Localization Methods Right
- BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation
- Hyperbolic Visual Embedding Learning for Zero-Shot Recognition
- Single-Stage Semantic Segmentation from Image Labels
Generative models and image synthesis
Learning Physics-Guided Face Relighting Under Directional Light (paper)
Relighting involves adjusting the lighting of an unseen source image with its corresponding directional light, towards the new desired directional light. The previous works give good results but are limited to smooth lighting and do not model non-diffuse effects such as cast shadows and specularities.
To be able to create precise and believable relighting results and generalizes to complex illumination conditions and challenging poses, the authors propose an end-to-end deep learning architecture that both delights and relights an image of a human face. This is done in two stages, as shown below.
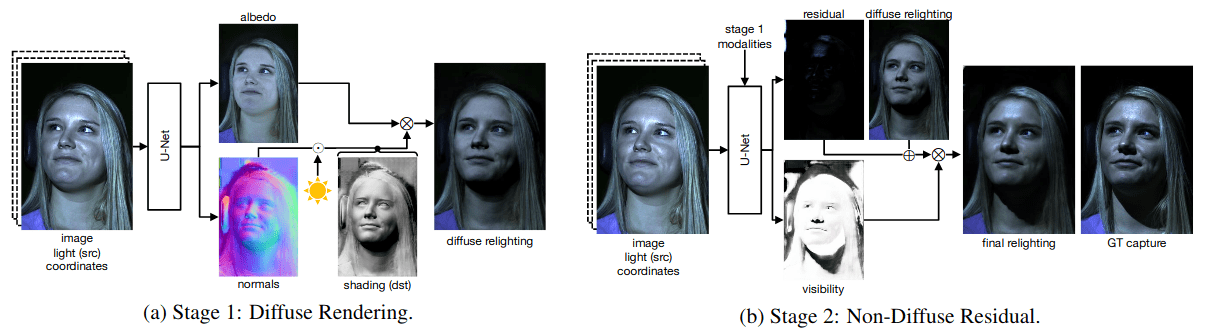
The first stage consists of predicting the albedo and normals of the input image using a Unet architecture, the desired directional light is then used with the normals to predict the shading and then the diffuse relighting. The outputs of the first stage are used in the second stage to predict the correct shading. The whole model is trained end-to-end with a generative adversarial network (GaN) loss similar to the one used in the pix2pix paper.
SynSin: End-to-End View Synthesis From a Single Image (paper)
The goal of view synthesis is to generate new views of a scene given one or more images. But this can be challenging, requiring an understanding of the 3D scene from images. To overcome this, current methods rely on multiple images, train on ground-truth depth, or are limited to synthetic data. The authors propose a novel end-to-end model for view synthesis from a single image at test time while being trained on real images without any ground-truth 3D information (e.g., depth).

SynSin takes an input image, the target image, and the desired relative pose (i.e., the desired rotation and translation). The input image is first passed through a feature network to embed it into a feature space at each pixel location, followed by depth prediction at each pixel via a depth regressor. Based on the features and the depth information, a point cloud representation is created, the relative pose (i.e., applying rotation and translation) is then used to render the features at the new view with a fully differentiable neural point cloud renderer. However, the projected features might have some artifacts (e.g., some unseen parts of the image are now visible in the new view, and need to be rendered), in order to fix this, a generator is used to fill the missing regions. The whole model is then trained end-to-end with: an L2 loss, a discriminator loss, and a perceptual loss, without requiring any depth information. At test time, the network takes an image and the target relative pose and outputs the image with the desired view.
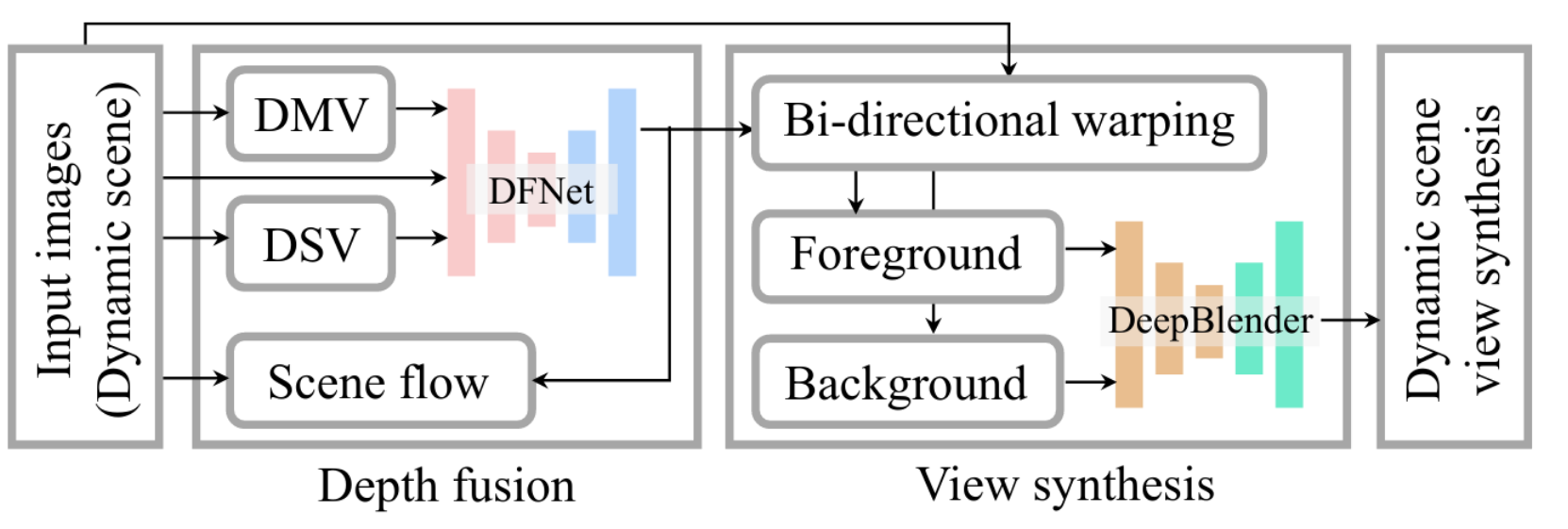
Novel View Synthesis of Dynamic Scenes with Globally Coherent Depths from a Monocular Camera (paper)
The objective in this paper is to synthesize an image from arbitrary views and times given a collection of images of a dynamic scene, i.e., a series of images captured by a single monocular camera from many the locations (image bellow, left). The method can produce a novel view from an arbitrary location within the original range of locations (image bellow, middle), and can also produce the dynamic content that appeared across any views in different times (image bellow, right). This is done using a single camera, without requiring a multiview system or human-specific priors as previous methods.

The authors combine the depth from multiview stereo (DMV) with the depth from a single view (DSV) using depth fusion network with the help of the input image from the target view, producing a scale-invariant and a complete depth map. With geometrically consistent depths across views, a novel view can be synthesized using a self-supervised rendering network that produces a photorealistic image in the presence of missing data with an adversarial loss and a reconstruction loss.
STEFANN: Scene Text Editor using Font Adaptive Neural Network (paper)
This paper presents a method to directly modify text in an image at a character level while maintaining the same style. This is done in two steps. First, a network called FANnet takes as input the source character we would like to modify and outputs the target character while keeping structural consistency and the style of the source. Second, the coloring network, Colornet, takes the output of the first stage and the source character and colors the target character while reserving visual consistency. After doing this process for each character of the text, the characters are placed in the in-painted background while maintaining the correct spacing between characters. Below are some examples of the results from the project’s webpage.

MixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation (paper)
MixNMatch is a conditional GAN capable of disentangling background, object pose, shape, and texture from real images with minimal supervision, i.e., bounding box annotations to model background. A trained model can then be used to arbitrarily combine the our factors to generate new images, including sketch2color, cartoon2img, and img2gif applications.

Given a collection of images of a single object category, the model is trained to simultaneously encode background, object pose, shape, and texture factors associated with each images into a disentangled latent code space, and then generate real looking image by combining latent factors from the disentangled code space. Four encoders are used to separately encode each latent code. Four different latent codes are then sampled and fed into the FineGAN generator to hierarchically generate images, the model is then trained with four image-code pair discriminators optimize the encoders and generator to match their joint image-code distributions.
StarGAN v2: Diverse Image Synthesis for Multiple Domains (paper)
The main objective in image-to-image translation (i.e., changing some attributes of an image, such as hair color) is to increase the quality and the diversity of the generated images, while maintaining high scalability over multiple domains (i.e., a domain refers to set of images having the same attribute value, like black hair). Given that existing methods address only one of these issues, resulting in either limited diversity or various models for all domains. StarGAN v2 tries to solves both issues simultaneously, using style codes instead of an explicit domain labels as in the first version of StarGAN.
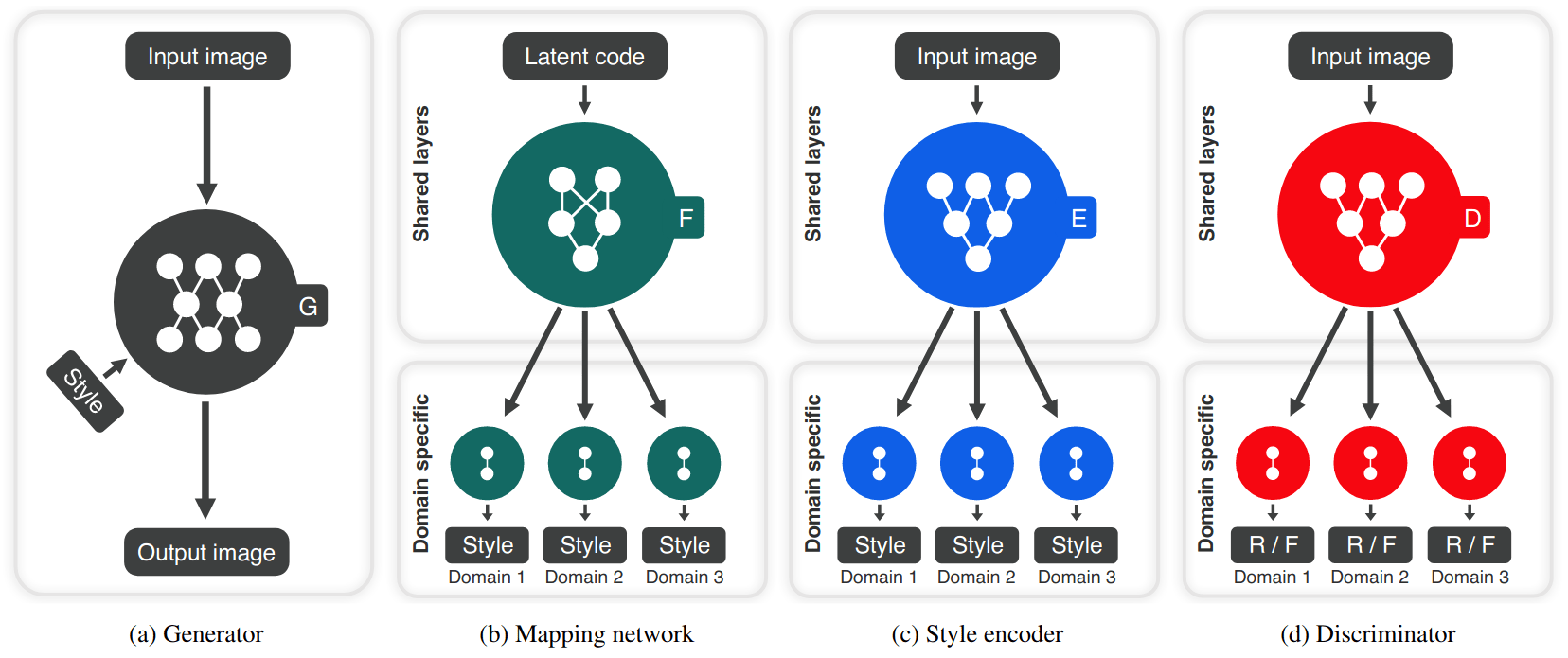
The StarGAN v2 model contains four modules: A generator that translates an input image into an output image with the desired domain-specific style code. A latent encoder (or a mapping network) that produces a style code for each domain, one of which is randomly selected during training. A style encoder that extracts the style code of an image, allowing the generator to perform reference-guided image synthesis, and a discriminator that distinguishes between real and fake (R/F) images from multiple domains. All modules except the generator contain multiple output branches, one of which is selected when training the corresponding domain. The model is then trained using an adversarial loss, a style reconstruction to force the generator to utilize the style code when generating the image, a style diversification loss to enable the generator to produce diverse images and a cycle loss to preserve the characteristics of each domain.
GAN Compression: Efficient Architectures for Interactive Conditional GANs (paper)
Conditional GANs (cGANs) give the ability to do controllable image synthesis for many computer vision and graphics applications. However, the computational resources needed for training them are orders of magnitude larger than that of traditional CNNs used for detection and recognition. For example, GANs require 10x to 500x more computation that image recognition models. To solve this problem, the authors propose a GAN compression approach based on distillation, channel pruning, and neural architecture search (NAS), resulting in a compressed model while maintaining the same performance.
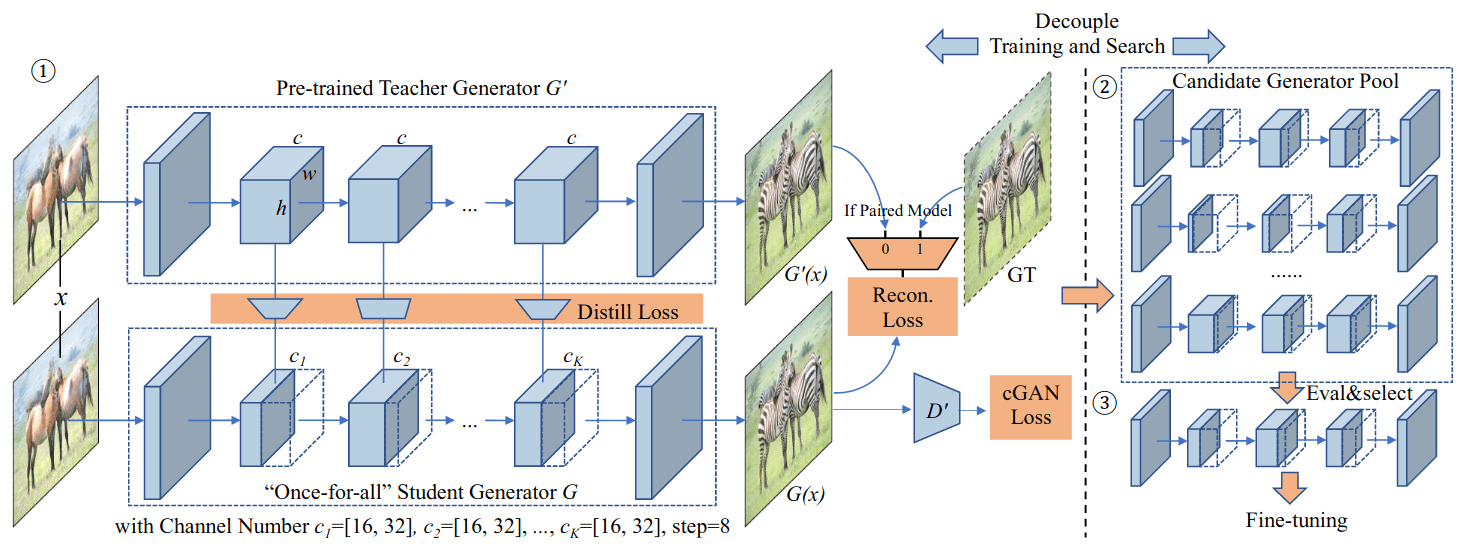
The proposed GAN Compression framework takes a pre-trained generator, considered as a teacher, which is first distilled into a smaller once-for-all student generator that contains all possible channel numbers through weight sharing, where different channel numbers are chosen for the student at each iteration. Now, in order to choose the correct number of channels of the student for each layer, many sub-generators are extracted from the once-for-all (student) generator and evaluated, creating the candidate generator pool. Finally, the best sub-generator with the desired compression ratio target and performance target (e.g., FID or mIoU) using one-shot NAS, the selected generator is then fine-tuned, resulting in the final compressed model.
Semantic Pyramid for Image Generation (paper)
Semantic Pyramid tries to bridge the gap between discriminative and generative models. This is done using a novel GAN-based model that utilizes the space of deep features learned by a pre-trained classification model. Given a set of features extracted from a reference image, the model generates diverse image samples, each with matching features at each semantic level of the classification model.
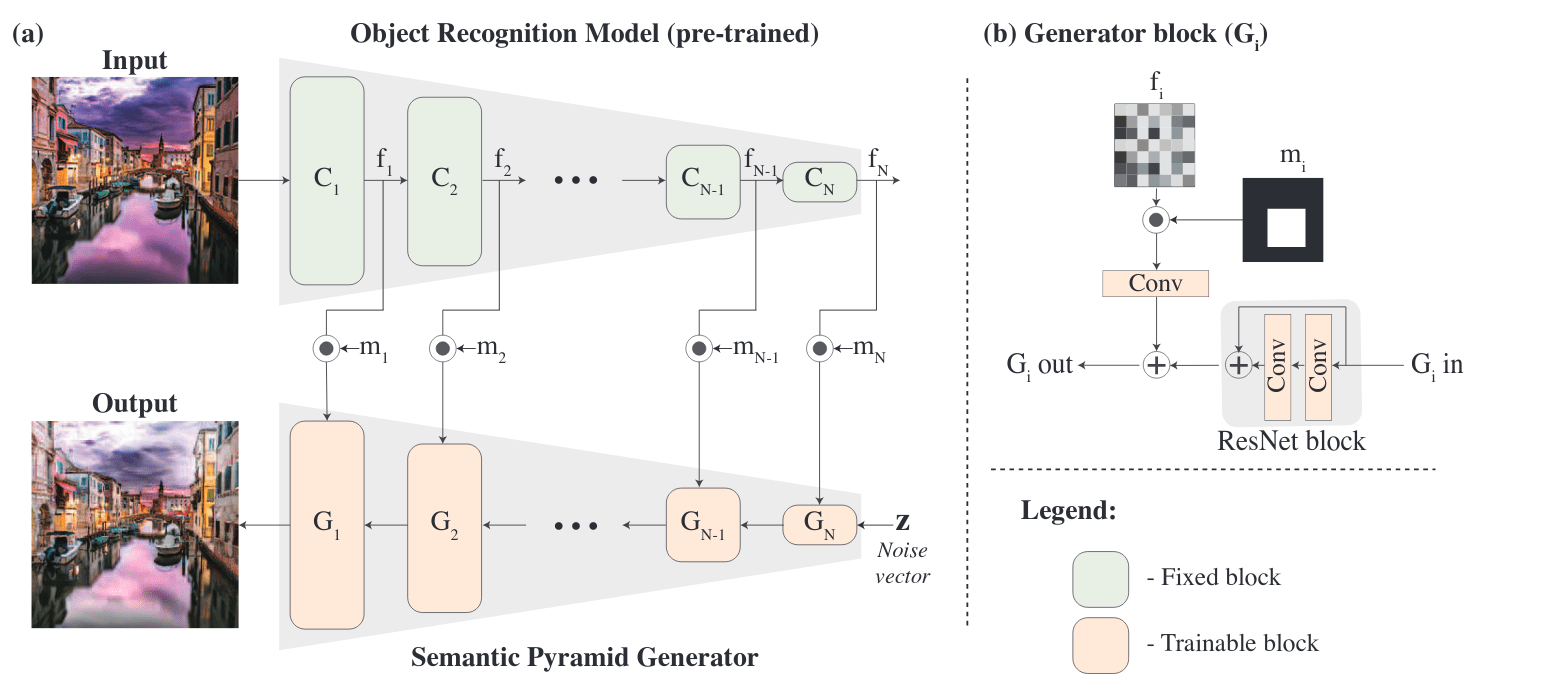
Concretely, given a pretrained classification network, a GAN network is designed with a generator with a similar architecture as the classification network. Each layer of the generator is trained to be conditioned on the previous layers, and the corresponding layers of the classification network. For example, conditioning the generator on the classification features close to the input results in an image similar to the input image of the classification model, with the possibility of exploring the sup-space of such image by sampling different noise vectors. On the other hand, conditioning on deeper layers results in a wider distribution of generated images. The model is trained with an adversarial loss to produce realistic images, a diversity loss to produce diverse images with different noises, and a reconstruction loss to match the features of the generated image to the reference image. Different regions of the image can be conditioned on different semantic levels using a masking operation \(m\), which can be used to semantically modify the image.
Analyzing and Improving the Image Quality of StyleGAN (paper)
In the first version of StyleGAN, the authors proposed an alternative generator architecture, capable of producing high-quality images and capable of separating high-level attributes (e.g., pose and identity when trained on human faces). This new architecture consisted of using a mapping network from the latent space \(\mathcal{Z}\) into an intermediate space \(\mathcal{W}\) to more closely match the distribution of features in the training set, and avoid the forbidden combinations present in \(\mathcal{Z}\). The intermediate latent vector is incorporated into the generator using Adaptive Instance Normalization (AdaIN) layers while a uniform noise is additively injected before each application of AdaIN, and trained in a progressive manner. Yielding impressive results in data-driven unconditional generative image modeling. However, the generated images still contain some artifacts, like water-splotches (more details: whichfaceisreal) and unchanged positions of face attributes like eyes.
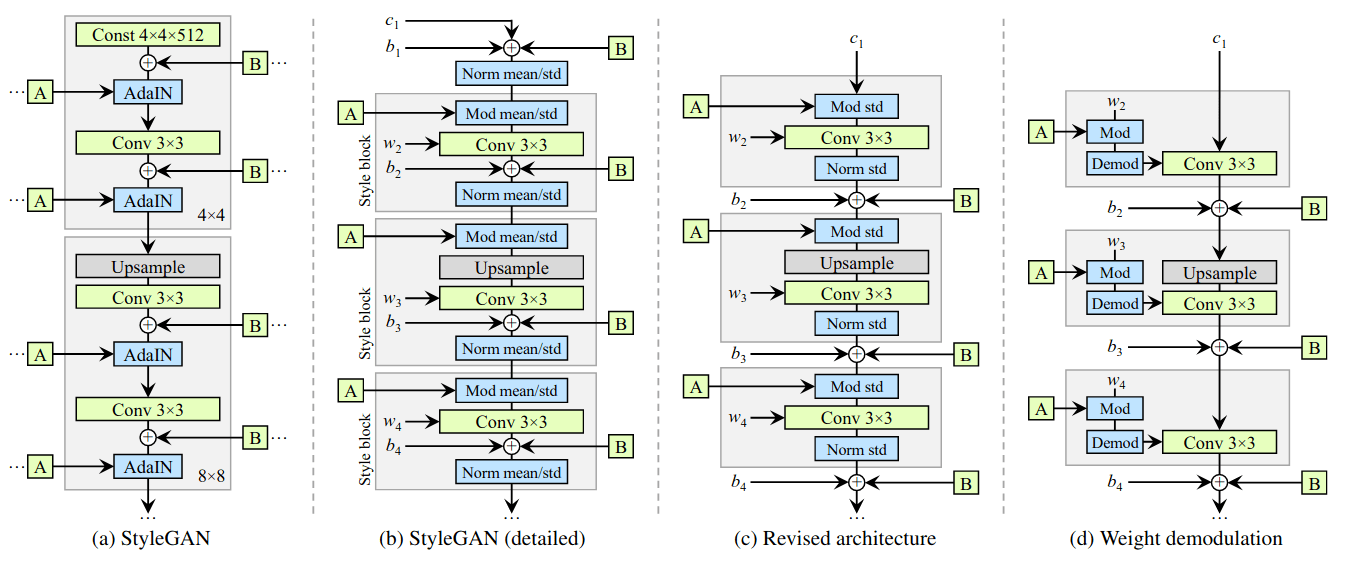
First, to avoid the droplet effects, which are results of the AdaIN discarding information in feature maps, AdaIN is replaced with a weight demodulation layer by removing some redundant operations, moving the addition of the noise to be outside of the active area of a style, and adjusting only the standard deviation per feature map. The progressive GAN training is removed to avoid the permanent positions of face attributes based on MSG-GAN. Finally, StyleGAN2 introduces a new regularization term to the loss to enforce smoother latent space interpolations based on the Jacobian matrix at a single position at the intermediate latent space.
Adversarial Latent Auto-encoders (paper)
Auto-Encoders (AE) are characterized by their simplicity and their capability of combining generative and representational properties by learning an encoder-generator map simultaneously. However, they do not have the same generative capabilities as GANs. The proposed Adversarial Latent Autoencoder (ALAE) retain the generative properties of GANs by learning an output data distribution with an adversarial strategy, with AE architecture where the latent distribution is learned from data to improve the disentanglement properties (i.e., the \(\mathcal{W}\) intermediate latent space of StyleGAN).
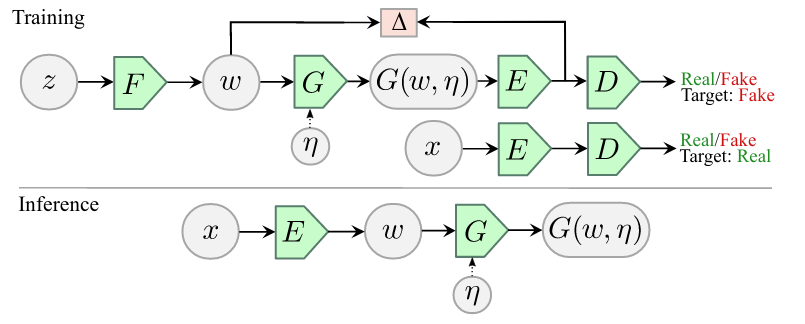
The ALAE architecture decomposes the generator G and the discriminator D in two networks: F, G, and E, D, where the latent spaces between F and G, and between E and D are considered same, and refereed to as the intermediate latent space \(\mathcal{W}\). In this case, the mapping network F is deterministic, while E and G are stochastic depending on an injected noise. The pair of networks (G,E) consist a generator-encoder network that auto-encodes the latent space \(\mathcal{W}\), and trained to minimize the discrepancy \(\Delta\) (e.g., an MSE loss) between the two distributions, i.e., the distribution at the input of G and the distribution of the output of E. As a whole, model is the trained by alternating between optimizing the GAN loss and the discrepancy \(\Delta\).
Other papers:
- Interpreting the Latent Space of GANs for Semantic Face Editing
- MaskGAN: Towards Diverse and Interactive Facial Image Manipulation
- Semantically Multi-modal Image Synthesis
- TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting
- Learning to Shadow Hand-drawn Sketches
- Wish You Were Here: Context-Aware Human Generation
- Disentangled Image Generation Through Structured Noise Injection
- MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks
- PatchVAE: Learning Local Latent Codes for Recognition
- Diverse Image Generation via Self-Conditioned GANs
- Towards Unsupervised Learning of Generative Models for 3D Controllable Image Synthesis
Representation Learning
Self-Supervised Learning of Pretext-Invariant Representations (paper)
Existing self-supervised learning methods consist of creating a pretext task, for example, diving the images into nine patches and solving a jigsaw puzzle on the permuted patches. These pretext tasks involve transforming an image, computing a representation of the transformed image, and predicting properties of transformation from that representation. As a result, the authors argue that the learned representation must covary with the transformation, and as a results, reducing the amount of learned semantic information. To solve this, they propose PIRL (Pretext-Invariant Representation Learning) to learn invariant representations with respect to the transformations and retain more semantic information.
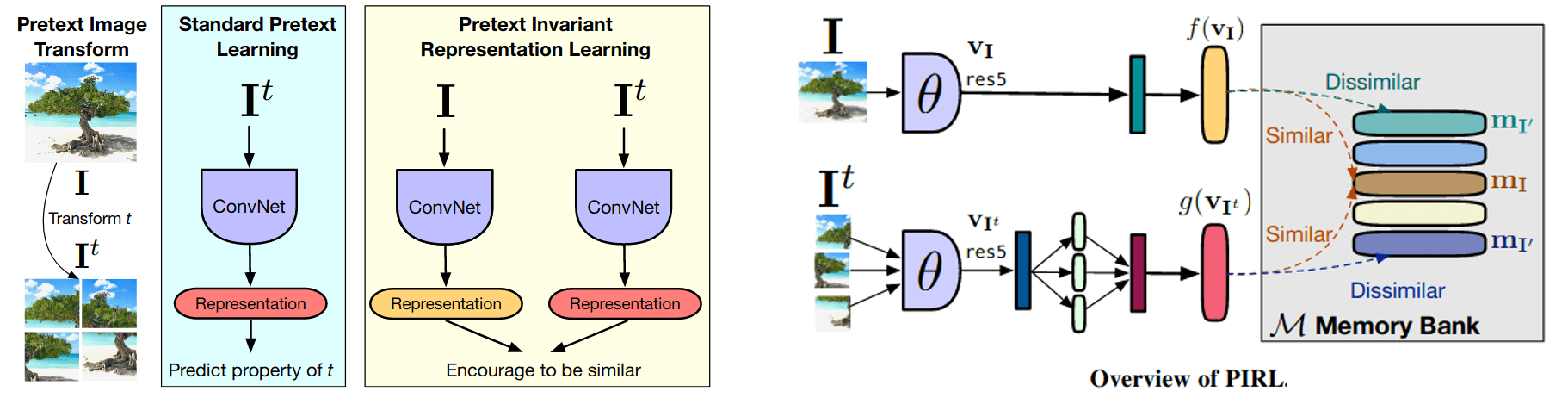
PIRL trains a network that produces image representations that are invariant to image transformations, and this is done by minimizing a contrastive loss, where the model is trained to differentiate a positive sample (i.e., an image and its transformed version) from N corresponding negative samples that are drawn uniformly at random from the dataset excluding the image used for the positive samples. Using a large number of negative samples is critical for noise contrastive estimation based losses. To this end, PIRL uses a memory bank containing feature representations for each example, where each representation at a given instance is an exponential moving average of previous representations.
ClusterFit: Improving generalization of visual representations (paper)
Weakly-supervised (e.g., hashtag prediction) and self-supervised (e.g., jigsaw puzzle) strategies are becoming increasingly popular for pretraining CNNs for visual downstream tasks. However, the learned representations using such methods may overfit to the pretraining objective given the limited training signal that can be extracted during pretraining, leading to a reduced generalization to downstream tasks.
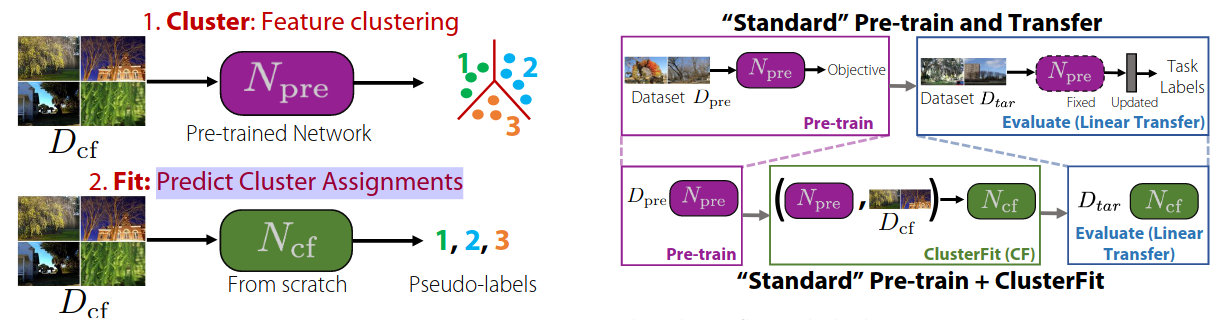
The idea of ClusterFit is quite simple, a network is first pretrained using some chosen pretraining task, be it self- or weakly-supervised, this network is then used to extract features for each image to then apply k-means clustering and assign a pseudo-label for each data points. The pseudo-labels can then be used for training a network from scratch, which will be more adapted to downstream tasks, with either linear probing or fine-tunning.
Momentum contrast for unsupervised visual representation learning (paper)
Recent works on unsupervised visual representation learning are based on minimizing the contrastive loss, which can be seen as building dynamic dictionaries, where the keys in the dictionary are sampled from data (e.g., images or patches) and are represented by an encoder network, which is then trained so that a query \(q\) is similar to a given key \(k\) (a positive sample) and dissimilar to the other keys (negative samples) .
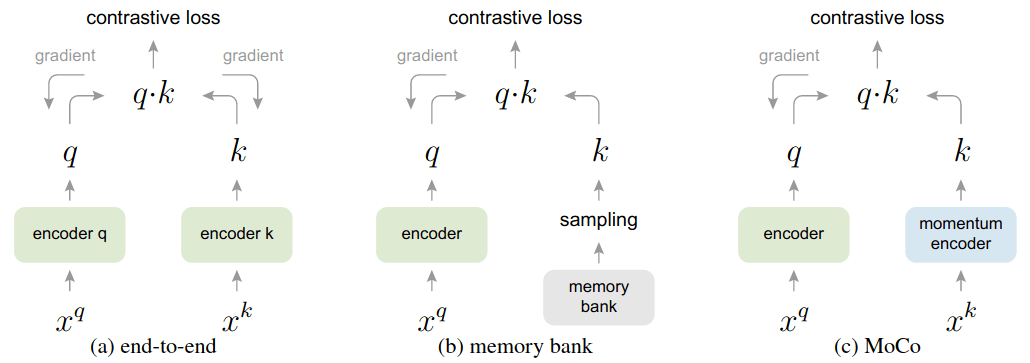
Momentum Contrast (MoCo) trains an encoder by matching an encoded query \(q\) to a dictionary of encoded keys using a contrastive loss. The dictionary keys are defined on-the-fly by a set of data samples, where the dictionary is built as a queue, with the current mini-batch enqueued and the oldest mini-batch dequeued, decoupling it from the mini-batch size. By using a queue, a large number of negatives can be used even outside of the current mini-batch. Additionally, the keys are encoded by a slowly progressing encoder, i.e., an exponential moving average of the query encoder, this way, the key encoder is slowly changing over time, producing stable predictions during the course of training. An other benefit of the query encoder is that the dequeue keys used as negatives are not too dissimilar to the current prediction of the key encoder, avoiding having a simple matching problem where the negatives are easily distinguishable from the positive sample.
Steering Self-Supervised Feature Learning Beyond Local Pixel Statistics (paper)
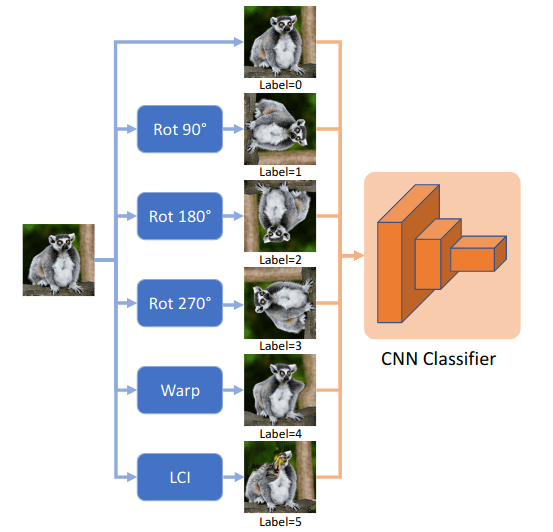
The authors argue that good image representations should capture both local and global image statistics to better generalize to downstream tasks, where local statistics capture the distribution of near by pixels, e.g., texture, and global statistics to capture the distribution of far away pixels and patches, e.g., shape. However, CNNs are more biased toward local statistics, and need to be explicitly forced to focus on global features for better generalization. To this end, the authors carefully choose a set of image transformations (i.e., warping, local inpainting and rotation) so that the network can not predict the applied transformation while only observing local statistics, forcing the network to focus on global pixel statistics. With the selected transformation, the network is then pretrained using a classification objective to predicted to label corresponding to the applied transformation.
Other papers:
- Self-Supervised Learning of Video-Induced Visual Invariances
- Circle Loss: A Unified Perspective of Pair Similarity Optimization
- Learning Representations by Predicting Bags of Visual Words
Computational photography
Learning to See Through Obstructions (paper)
The paper propose a learning based approach for removing unwanted obstructions (examples bellow). The method uses a multi-frame obstruction removal algorithm that exploits the advantages of both optimization-based and learning-based methods, alternating between dense motion estimation and background/obstruction layer reconstruction steps in a coarse-to-fine manner. By modeling of the dense motion, detailed content in the respective layers can be progressively recovered, gradually separating the background from the unwanted occlusion layers. The first staeg consists of flow decomposition, followed by two subsequent stages, background and obstruction layer reconstruction stages, and finally optical flow refinement.

Background Matting: The World is Your Green Screen (paper)
The process of separating an image into foreground and background, called matting, generally requires a green screen background or a manually created trimap to produce a good matte, to then allow placing the extracted foreground in the desired background. In this paper, the authors propose to use a captured background as an estimate of the true background which is then used to solve for the foreground and alpha value (i.e., every pixel in the image is represented as a combination of foreground and background with a weight alpha).

The model takes as input an image or video of a person in front of a static, natural background, plus an image of just the background. A deep matting network then extracts foreground color and alpha at each spatial location for a given input frame, augmented with background, soft segmentation, and optionally nearby video frames, in addition to a discriminator network that guides the training to generate realistic results. The whole model is trained end-to-end using a combination of a supervised and self-supervised adversarial losses.
3D Photography using Context-aware Layered Depth Inpainting (paper)
The objective of the paper is to synthesize content in regions occluded in the input image from a single RGB-D image. The proposed method consists of a three steps pipeline. First, given the RGB-D image, a preprocessing step is applied by filtering the depth and color input using a bilateral median filter, the raw discontinuities are then detected using disparity thresholds to estimate the depth edges. Followed by a detection of a context/synthesis regions for each detected depth. Given the color, depth and edge information, the last step consist of depth edge inpating guided by color and depth inpating, resulting a new view as seen in the GIF bellow (taken from authors YT video).

PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models (paper)
The goal of single-image super-resolution is to output a corresponding high-resolution (HR) image from a low-resolution (LR) one. Previous methods train with a supervised loss that measures the pixel-wise average distance between the ground-truth HR image and the output of the model. However, multiple HR images that map to the same LR image exist, and such methods try to match the true HR image, outputting a per-pixel average of all the possible HR images that do not contain a lot details in high frequency regions, resulting in a blurry HR output.
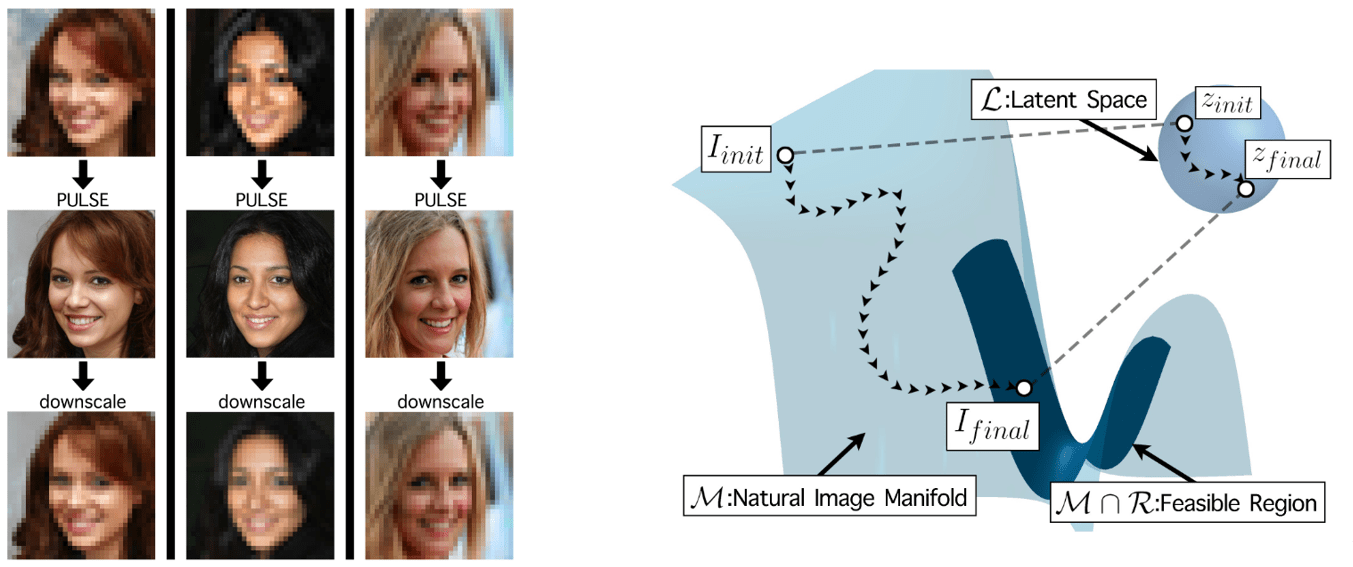
PULSE seeks to find only one plausible HR image from the set of possible HR images that down-scale to the same LR input, and can be trained in a self-supervised manner without the need for a labeled dataset, making the method more flexible and not confined to a specific degradation operator. Specifically, instead of starting with the LR image and slowly adding detail, PULSE traverses the high-resolution natural image manifold, searching for images that downscale to the original LR image. This is done by minimizing a distance measure between the down-scaled HR output of the generator, taking as input the LR image, and the LR image itself. Additionally, the search space is restricted to guarantee that outputs of the generator are realistic by using the unit sphere in \(d\) dimensional Euclidean space as the latent space.
Other papers:
- Learning to Autofocus
- Lighthouse: Predicting Lighting Volumes for Spatially-Coherent Illumination
- Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution
- Explorable Super Resolution
- Deep Optics for Single-shot High-dynamic-range Imaging
- Seeing the World in a Bag of Chips
Transfer/Low-shot/Semi/Unsupervised Learning
Conditional Channel Gated Networks for Task-Aware Continual Learning (paper)
In the case where the training examples come in a sequence of sub-tasks, deep nets where gradient-based optimization is required are subject to catastrophic forgetting, where the learned information from previous tasks is lost. Continual learning tries to solve this by allowing the models to protect and preserve the acquired information while still being capable of extracting new information from new tasks. Similar to the gating mechanism in LSTMs/GRUs, the authors propose a channel-gating module where only a subset of the feature maps are selected depending on the current task. This way, the important filters are protected to avoid a loss in performance of the model on previously learned tasks, additionally, by selecting a limited set of kernels to be updated, the model will still have the capacity to learn new tasks.
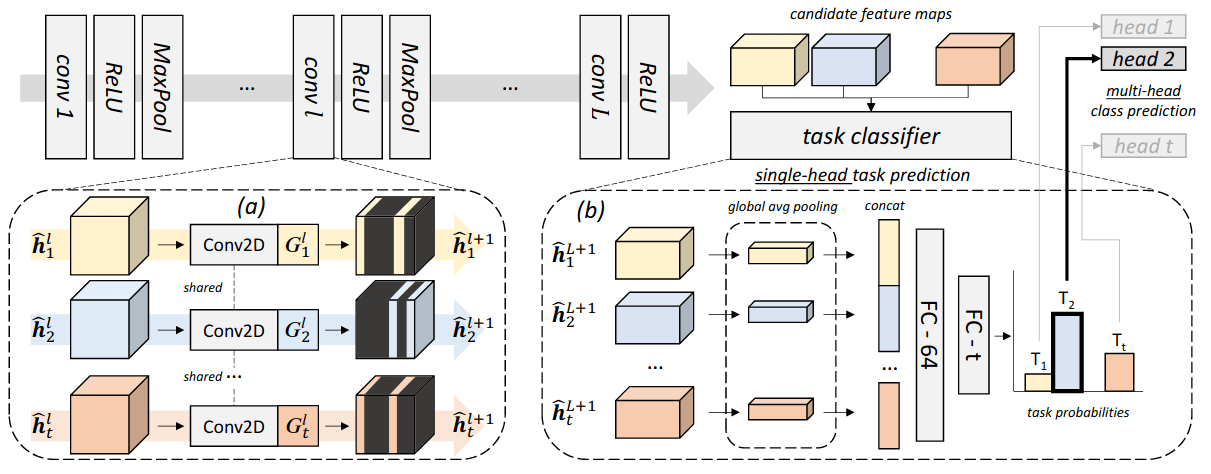
The paper also introduces a task classifier to overcome the need to know which task the model is being applied to at test time, the task classifier is trained to predict the task at train time and selects which CNN features to pass to the fully-connected layers for classification. However, the task classifier is also subject to catastrophic forgetting, and the authors propose to train it with Episodic memory and Generative memory to avoid this.
Few-Shot Learning via Embedding Adaptation with Set-to-Set Functions (paper)
Few-Shot Learning consists of learning a well-performing model with N-classes, K examples in each class (i.e., referred to as a N-way, K-shot task), but a high-capacity deep net is easily prone to over-fitting with limited training data. Many few-shot learning methods (e.g., Prototypical Networks) address this by learning an instance embedding function from seen classes during training where there are ample labeled instances, and then apply a simple function to the embeddings of the new instances from unseen classes with limited labels at test time. However, the learned embeddings are task-agnostic given that the learned the embedding function is not optimally discriminative with respect to the unseen classes.
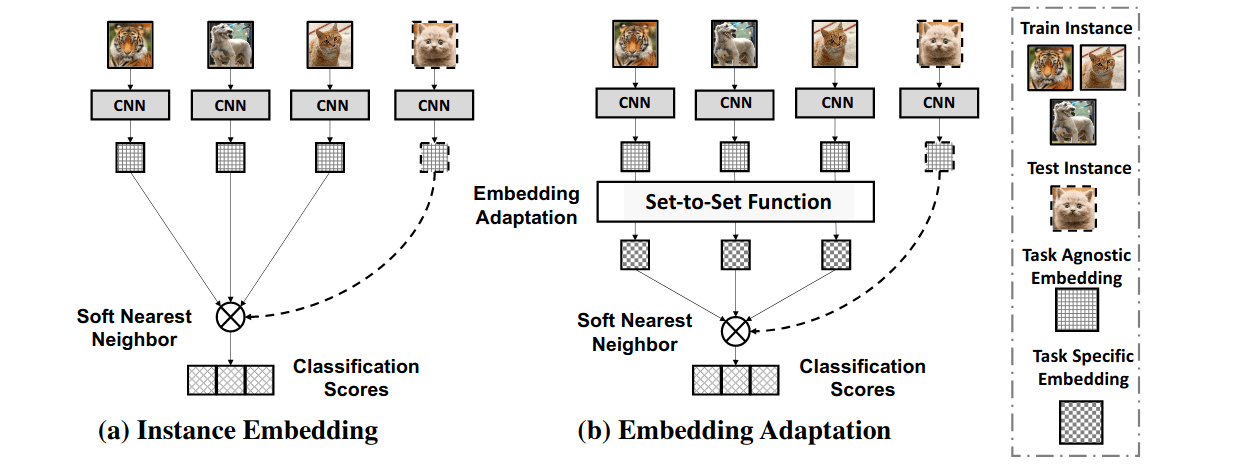
The authors propose to adapt the instance embeddings to the target classification task with a set-to-set function, yielding embeddings that are task-specific and are discriminative. To have task-specific embeddings, an additional adaptation step is conducted, where the embedding function is transformed with a set-to-set function that contextualizes over the image instances of a set, to enable strong co-adaptation of each item. The authors tested many set-to-set functions, such as BiLSTMs, Graph Convolutional Networks, and Transformers, and found that Transformers work bets in this case.
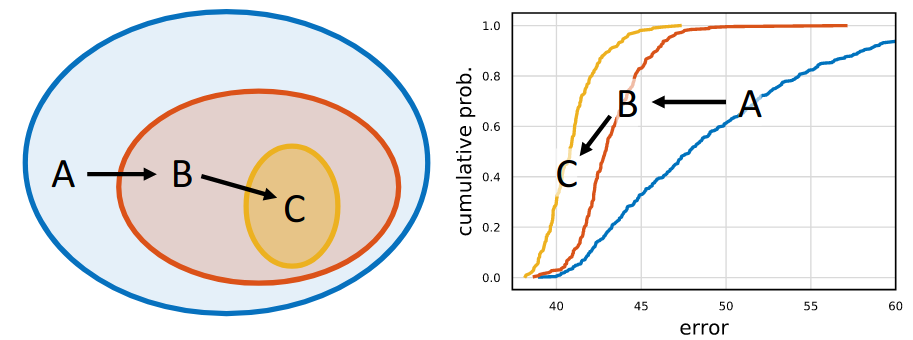
Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations (paper)
In cases where we are provided with a small labeled set, the performance of deep nets degrades on ambiguous samples as a result of placing the decision boundary close to high-density regions (right figure below). A common solution is to minimize the entropy, but one side effect caused by entropy minimization is the reduction of the prediction diversity, where ambiguous samples are classified as belonging to the most dominant classes, i.e., an increase in discriminability but a reduction in diversity.
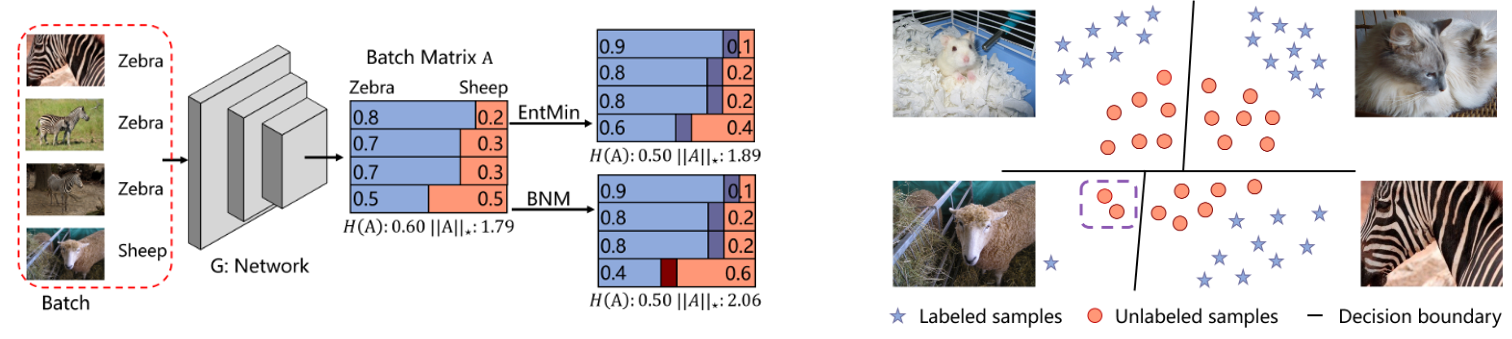
The paper investigates ways to increase both the discriminability: outputting highly certain predictions, and the diversity: predicting all the categories somewhat equally. By analyzing the rank of the output matrix \(A \in \mathbb{R}^{B \times C}\), with a batch of \(B\) samples and \(C\) classes, the authors find that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and the rank of \(A\), and propose Batch Nuclear-norm Maximization (BNM) and apply it on the output matrix \(A\) to increase the performance in cases where we have a limited amount of labels, such as semi-supervised learning and domain adaptation.
Other papers:
- Distilling Effective Supervision from Severe Label Noise
- Mask Encoding for Single Shot Instance Segmentation
- WCP: Worst-Case Perturbations for Semi-Supervised Deep Learning
- Meta-Learning of Neural Architectures for Few-Shot Learning
- Towards Inheritable Models for Open-Set Domain Adaptation
- Open Compound Domain Adaptation)
Vision and Language
12-in-1: Multi-Task Vision and Language Representation Learning (paper)
Vision-and-language based methods often focus on a small set of independent tasks that are studied in isolation. However, the authors point that visually-grounded language understanding skills required for success at each of these tasks overlap significantly. To this end, the paper proposes a large-scale, multi-task training regime with a single model trained on 12 datasets from four broad categories of tasks: visual question answering, caption-based image retrieval, grounding referring expressions, and multi-modal verification. Using a single model helps reduce the number of parameters from approximately 3 billion parameters to 270 million while simultaneously improving the performances across tasks.

The model is based on ViLBERT, where each task has a task-specific head network that branches off a common, shared trunk (i.e., ViLBERT model). With 6 task heads, 12 datasets, and over 4.4 million individual training instances, multi-task training of this scale is hard to control. To overcome this, all the models are first pretrained on the same dataset. Then a round-robin batch sampling is used to cycle through each task from the beginning of multi-task training, with an early stopping for stopping a given task where some over-fitting is observed, with the possibility of restarting the training to avoid catastrophic forgetting.
Other papers:
- Sign Language Transformers: Joint End-to-End Sign Language Recognition and Translation
- Counterfactual Vision and Language Learning
- Iterative Context-Aware Graph Inference for Visual Dialog
- Meshed-Memory Transformer for Image Captioning
- Visual Grounding in Video for Unsupervised Word Translation
- PhraseCut: Language-Based Image Segmentation in the Wild
The rest
This post turned into a long one very quickly, so in order to avoid ending-up with a 1h long reading session, I will simply list some papers I came across in case the the reader is interested in the subjects.
Click to expand
Efficient training & inference:
- MnasFPN: Learning Latency-aware Pyramid Architecture for Object Detection on Mobile Devices
- Fast Sparse ConvNets
- GhostNet: More Features from Cheap Operations
- Forward and Backward Information Retention for Accurate Binary Neural Networks
- Sideways: Depth-Parallel Training of Video Models
- Butterfly Transform: An Efficient FFT Based Neural Architecture Design
3D applications and methods:
- SuperGlue: Learning Feature Matching with Graph Neural Networks
- Unsupervised Learning of Probably Symmetric Deformable 3D Objects From Images in the Wild
- PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
- BSP-Net: Generating Compact Meshes via Binary Space Partitioning
- Single-view view synthesis with multiplane images
- Three-Dimensional Reconstruction of Human Interactions
- Generating 3D People in Scenes Without People
- High-Dimensional Convolutional Networks for Geometric Pattern Recognition
- Shape correspondence using anisotropic Chebyshev spectral CNNs
Face, gesture, and body pose:
- HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
- DeepCap: Monocular Human Performance Capture Using Weak Supervision
- Transferring Dense Pose to Proximal Animal Classes
- Coherent Reconstruction of Multiple Humans from a Single Image
- VIBE: Video Inference for Human Body Pose and Shape Estimation
Video & Scene analysis and understanding:
- Self-Supervised Scene De-occlusion
- Unbiased Scene Graph Generation from Biased Training
- Counting Out Time: Class Agnostic Video Repetition Counting in the Wild
- Footprints and Free Space From a Single Color Image
- Action Genome: Actions As Compositions of Spatio-Temporal Scene Graphs
- End-to-End Learning of Visual Representations From Uncurated Instructional Videos