The 2020 European Conference on Computer Vision took place online, from 23 to 28 August, and consisted of 1360 papers, divided into 104 orals, 160 spotlights and the rest of 1096 papers as posters. In addition to 45 workshops and 16 tutorials. As it is the case in recent years with ML and CV conferences, the huge number of papers can be overwhelming at times. Similar to my CVPR2020 post, to get a grasp of the general trends of the conference this year, I will present in this blog post a sort of a snapshot of the conference by summarizing some papers (& listing some) that grabbed my attention.
First, some useful links:
- All of the papers can be found here: ECCV Conference Papers
- A list of available presentations on YT: Crossminds ECCV. In addition to this YT playlist.
- One sentence description of all ECCV-2020 papers: ECCV Paper Digest
- ECCV virtual website: ECCV papers and presentations
Disclaimer: This post is not a representation of the papers and subjects presented in ECCV 2020; it is just a personnel overview of what I found interesting. Any feedback is welcomed!
- General Statistics
- Recognition, Detection, Segmentation and Pose Estimation
- Semi-Supervised, Unsupervised, Transfer, Representation & Few-Shot Learning
- 3D Computer Vision & Robotics
- Image and Video Synthesis
- Vision and Language
- The Rest
General Statistics
The statistics presented in this section are taken from the official Opening & Awards presentation. Let’s start by some general statistics:
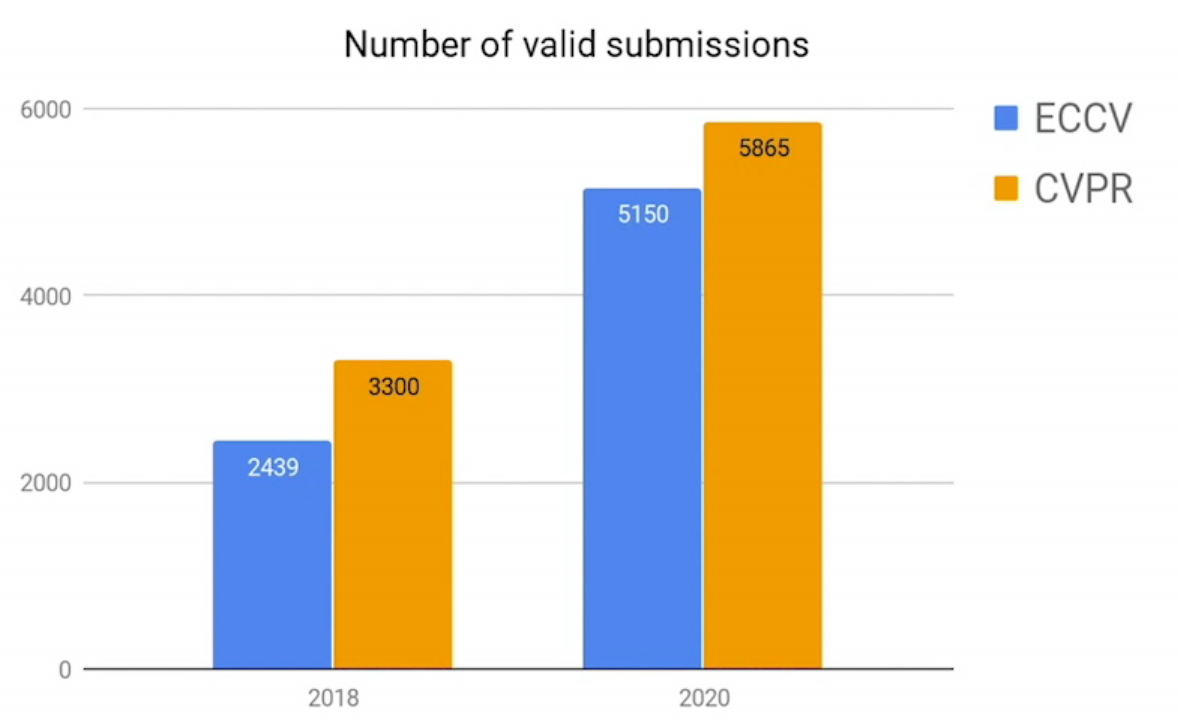
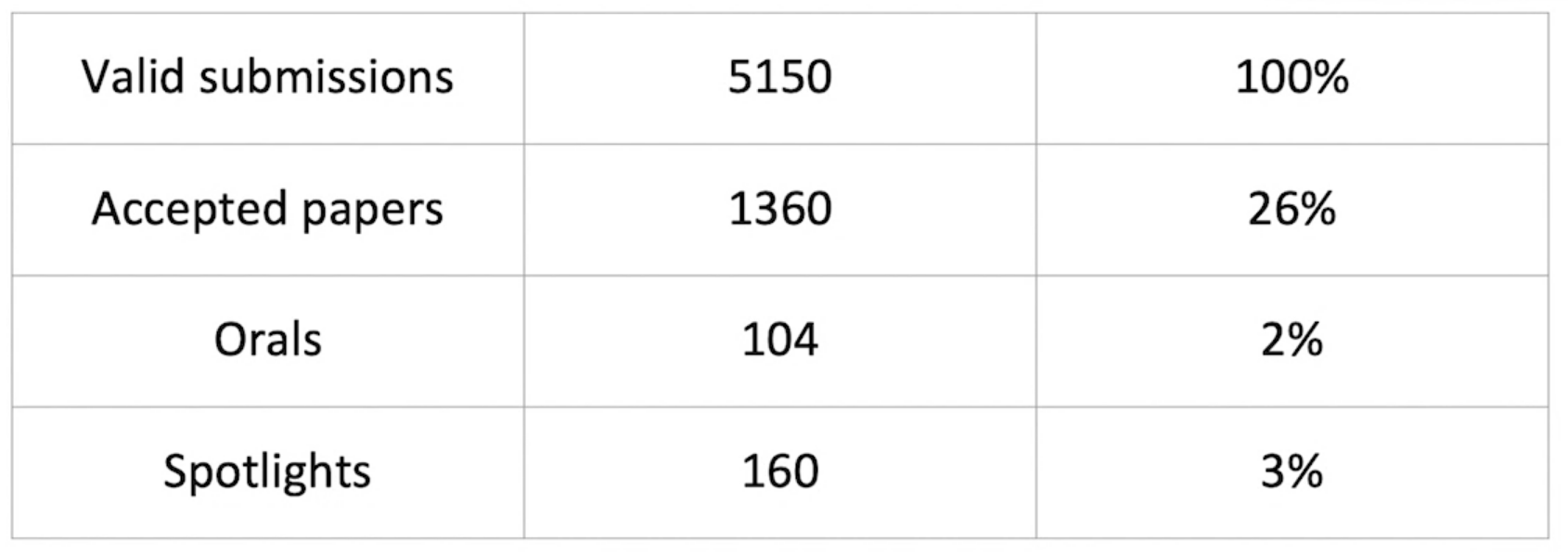
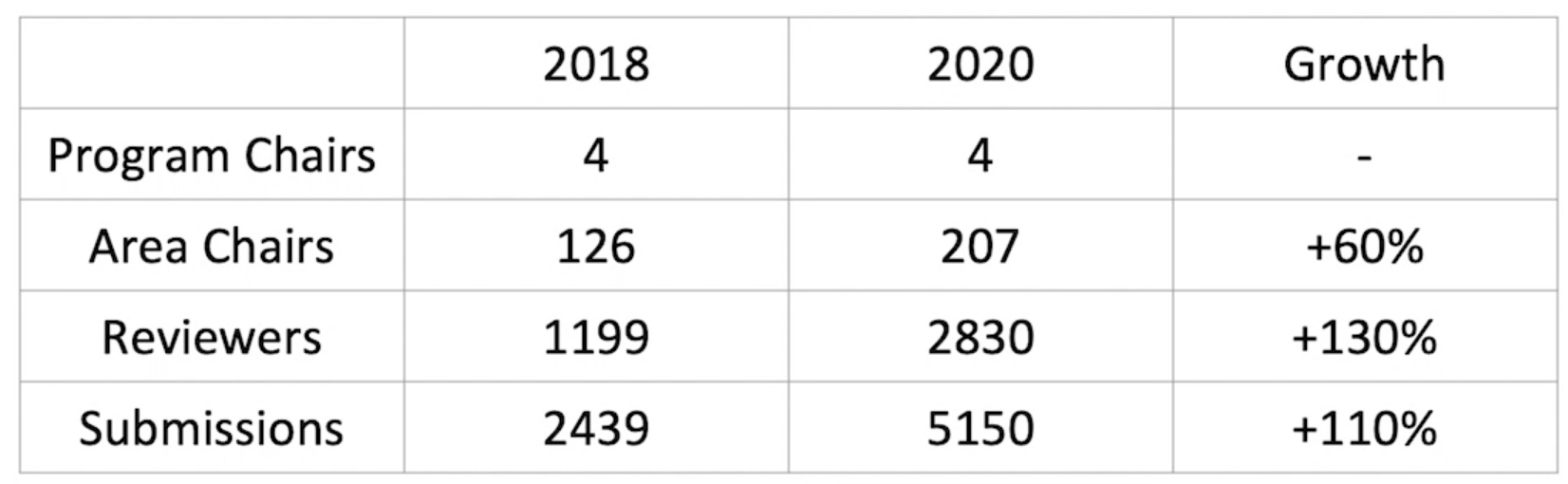
The trends of earlier years continued with more than 200% increase in submitted papers compared to the 2018 conference, and with a similar number of papers to CVPR 2020. As expected, this increase is joined by a corresponding increase in the number of reviewers and area chairs to accommodate this expansion.
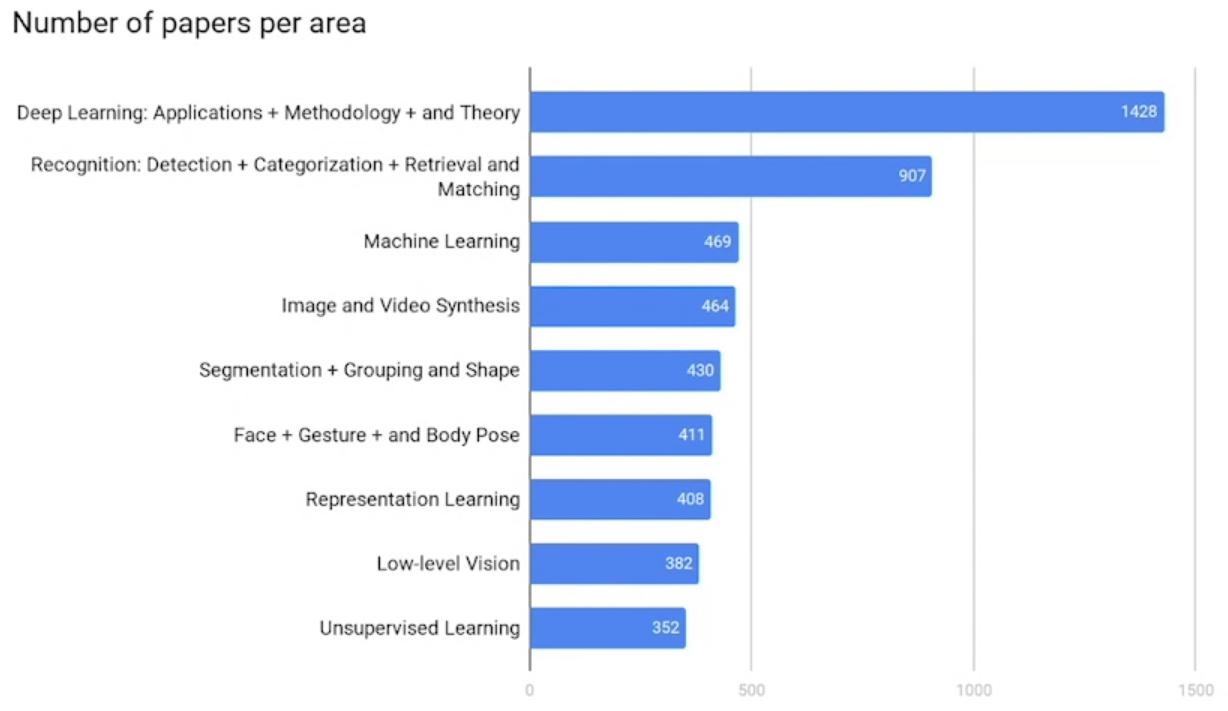
As expected, the majority of the accepted papers focus on topics related to deep learning, recognition, detection, and understanding. Similar to CVPR 2020, we see an increasing interest in growing areas such as label-efficient methods (e.g., unsupervised learning) and low-level vision.
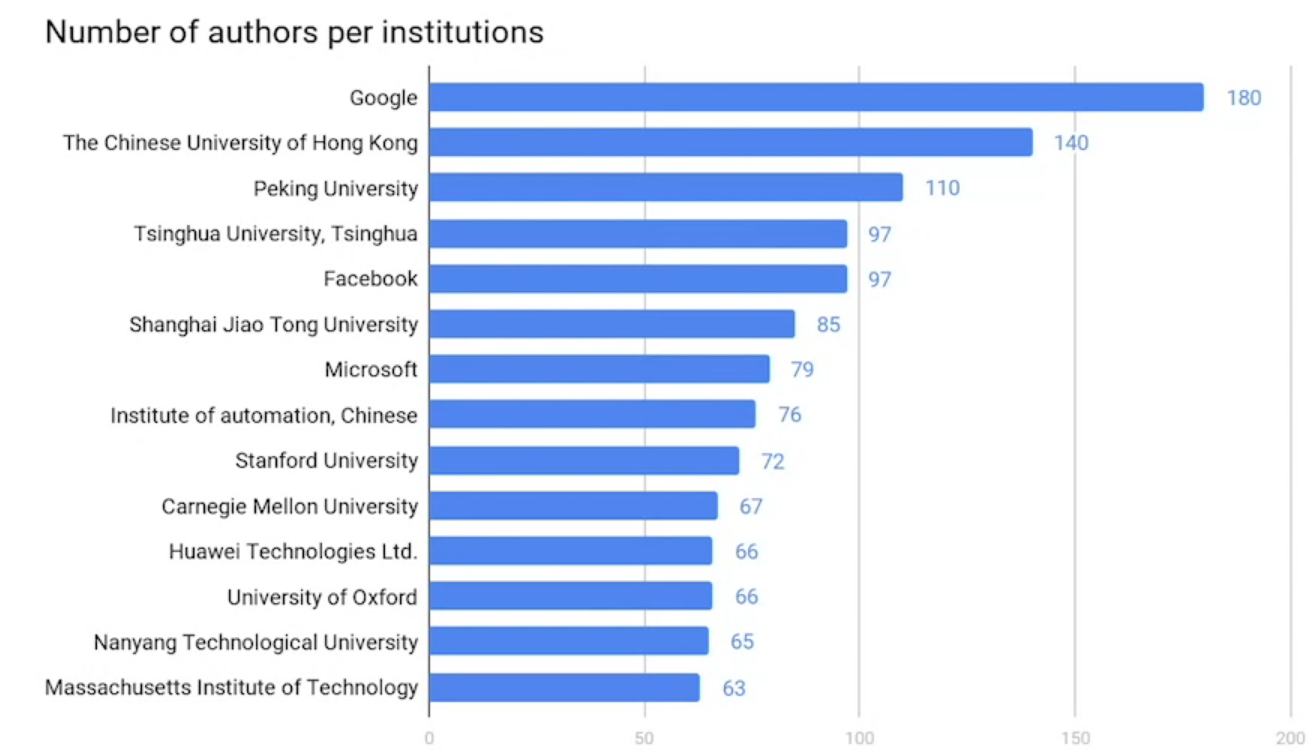
In terms of institutions; similar to ICML this year, Google takes the lead with 180 authors, followed by The Chinese University of Hong Kong with 140 authors and Peking University with 110 authors.
In the next sections, we’ll present some paper summaries by subject.
Recognition, Detection, Segmentation and Pose Estimation
End-to-End Object Detection with Transformers (paper)
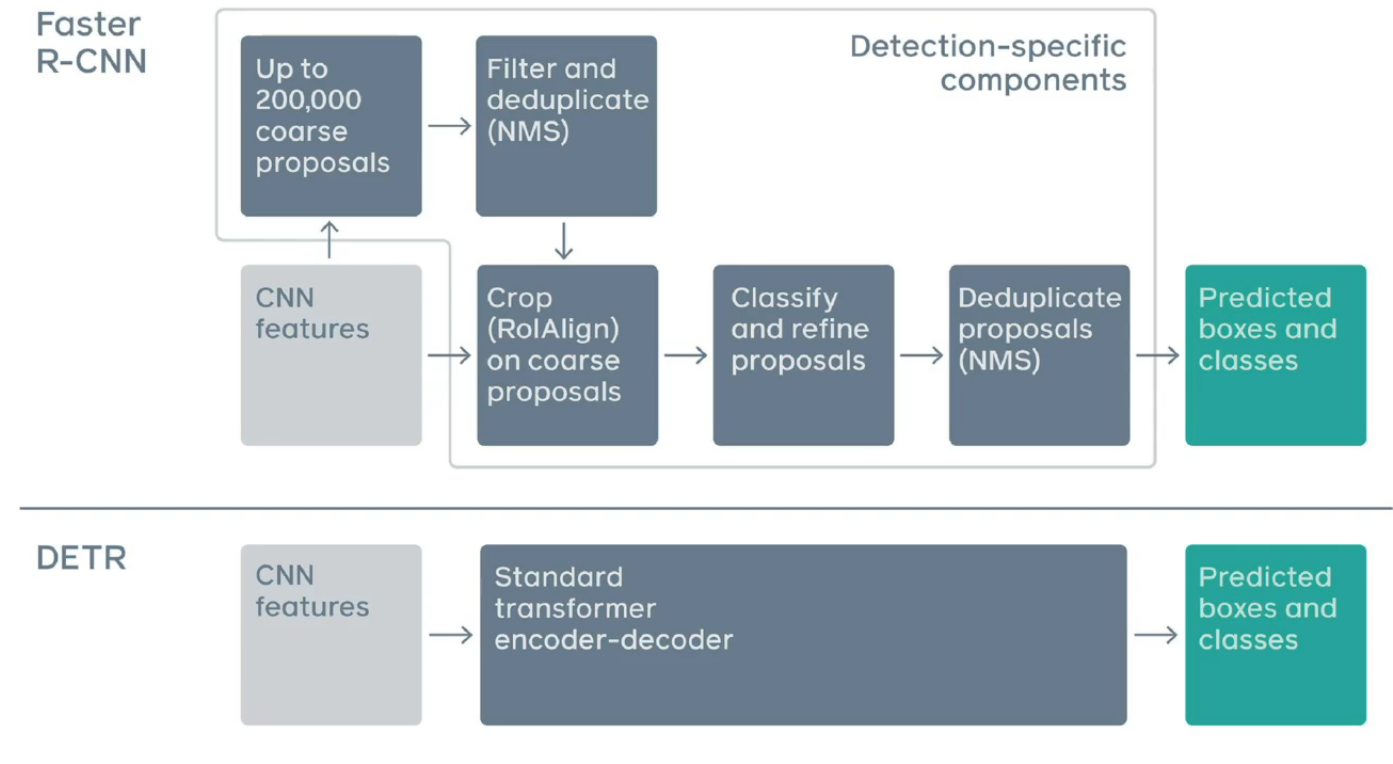
The task of object detection consists of localizing and classifying objects visible given an input image. The popular framework for object detection consist of pre-defining a set of boxes (ie., a set of geometric priors like anchors or region proposals), which are first classified, followed by a regression step to the adjust the dimensions of the predefined box, and then a post-processing step to remove duplicate predictions. However, this approach requires selecting a subset of candidate boxes to classify, and is not typically end-to-end differentiable. In this paper, the authors propose DETR (DEtection TRansformer), an end-to-end fully differentiable approach with no geometric priors. Bellow is a comparison of DETR and Faster R-CNN pipelines (image taken from the authors presentation), highlighting the holistic nature of the approach.
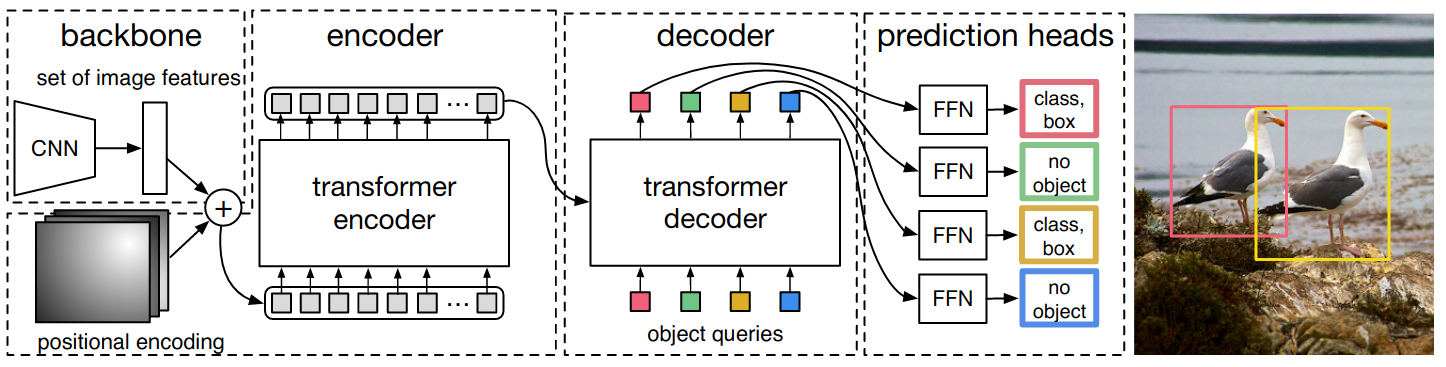
DETR is based on the encoder-decoder transformer architecture. The model consists of three components: the CNN feature extractor, the encoder, and the decoder. A given image is first passed through the feature extractor to get image features. Then, positional encodings generated using sinusoids at different frequencies are added to the features to retain the 2D structure of the image. The resulting features are then passed through the transformer encoder to aggregate information across features and separate the object instances. For decoding, object queries are passed to the decoder with the encoded feature producing the output feature vectors. These queries are a fixed set of learned embeddings called object queries, which are randomly initialized embeddings that are learned during training then fixed during evaluation, and their number defines an upper bound on the number of objects the model can detect. Finally, the output feature vectors are fed through a (shared) fully connected layer to predict the class and bounding box for each query. To compute the loss and train the model, the outputs are matched with the ground truths with a one-to-one matching using the Hungarian algorithm.
MutualNet: Adaptive ConvNet via Mutual Learning from Network Width and Resolution (paper)
Traditional neural network can only be used if a specific amount of compute is available, and if the resource constraints are not met, the model becomes unusable. However, this can greatly limit the usage of the models in real applications. For example, if the model is used for in-phone inference, the computational constrains are always changing depending on the load and the phone’s battery charge. A simple solution is to keep several models of different sizes on the device, and use the one with the corresponding constrains each time, but this requires a large amount of memory and cannot be scaled to different constraints. Recent methods like S-Net and US-Net sample sub-networks during training so the model can be used at different width during deployment. But the performance drops dramatically with very low constraints.
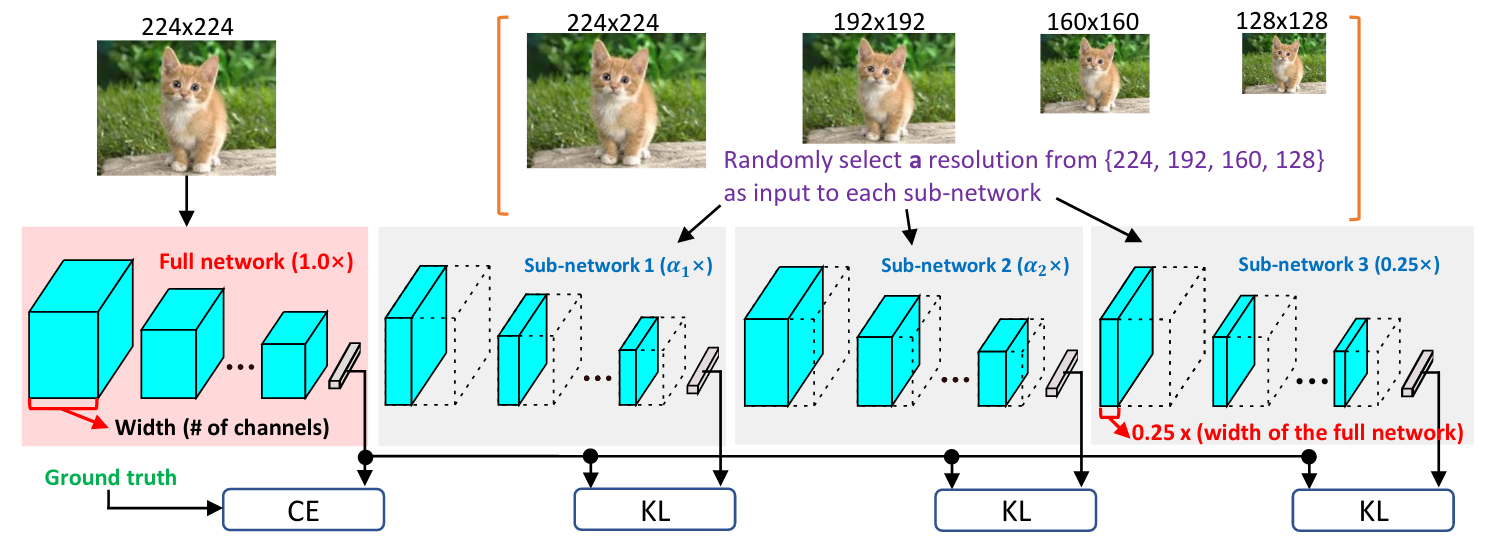
This paper proposes to leverage both the network scale and the input scale to find a good trade-off between the accuracy and the computational efficiency. As illustrated above, for a given training iteration, four sub-networks are sampled, a full one and three sub-networks with varying widths. The full network is trained on the original size of the image with the ground-truth labels using the standard cross-entropy loss, while the rest of the sub-networks are trained with randomly down-scaled version of the input image using KL divergence loss between their outputs and the output of the full network (ie., a distillation loss). This way, each sub-network will be able to learn multi-scale representations from both the input scale and the network scale. During deployment, and given a specific resource constraint, the optimal combination of network scale and input scale can be chosen for inference.
Gradient Centralization: A New Optimization Technique for Deep Neural Networks (paper)
Using second order statistics such as mean and variance during optimization to perform some form standardization of the activations or network’s weight, such as Batch norm or weight norm, have become an important component of neural network training. So, instead of operating on the weights or the activations with additional normalization modules, Gradient Centralization (GC) operates directly on gradients by centralizing the gradient vectors to have zero mean, which can smooth and accelerate the training process of neural networks and even improve the model generalization performance.
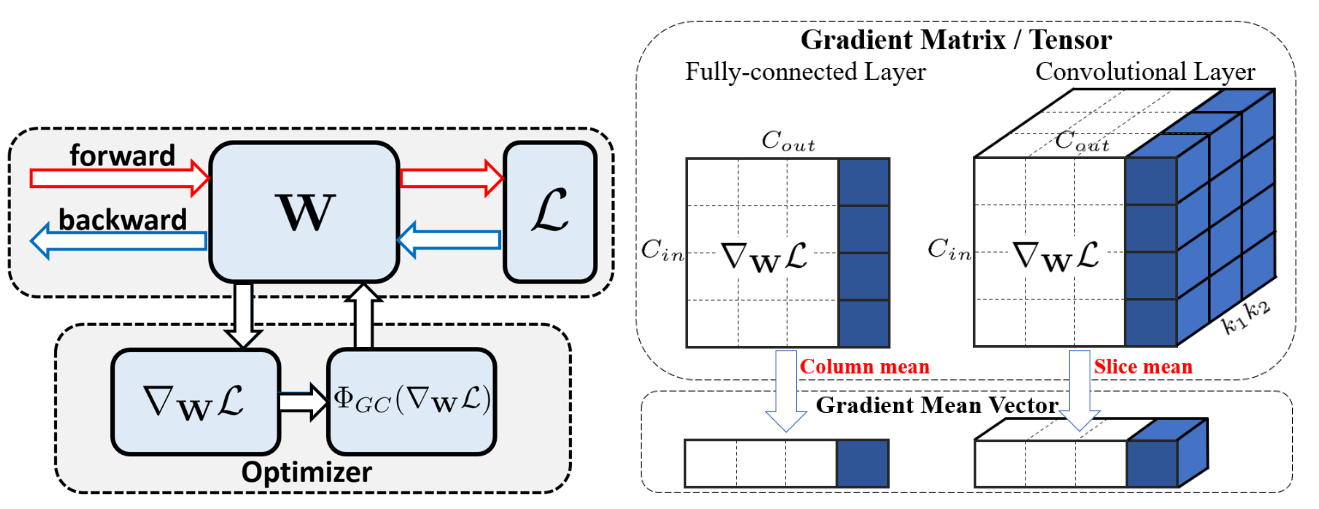
The GC operator, given the computed gradients, first computes the mean of the gradient vectors as illustrated above, then removes the mean of them. Formally, for a weight vector \(\mathbf{w}_i\) whose gradient is \(\nabla_{\mathbf{w}_{i}} \mathcal{L}(i=1,2, \ldots, N)\), the GC operator \(\Phi_{G C}\) is defined as:
\[\Phi_{G C}\left(\nabla_{\mathbf{w}_{i}} \mathcal{L}\right)=\nabla_{\mathbf{w}_{i}} \mathcal{L}-\frac{1}{M} \sum_{j=1}^{M} \nabla_{w_{i, j}} \mathcal{L}\]Smooth-AP: Smoothing the Path Towards Large-Scale Image Retrieval (paper)
In image retrieval, the objective is to retrieve images of the same class as the query image from a large collection of images. This tasks differs from classification where the classes encountered during testing were already seen during training, in image retrieval, we might get an image with a novel class and we need to fetch similar images, ie., an open set problem. The general pipeline of image retrieval consists of extracting embeddings for the query image, and also embeddings for all of image collection using a CNN feature extractor, compute the cosine similarity score between each pair, then rank the images in the collection based on such a similarity. The feature extractor is then trained to have a good ranking. The ranking performance is measured using Average Precision (AP), computing the sum of the rank of each positive over its rank on the whole image collection. However, computing the ranking of a given image consists of a thresholding operation using a Heaviside step function, making it non-differentiable, so we cannot train the model end-to-end to directly optimize the ranking.
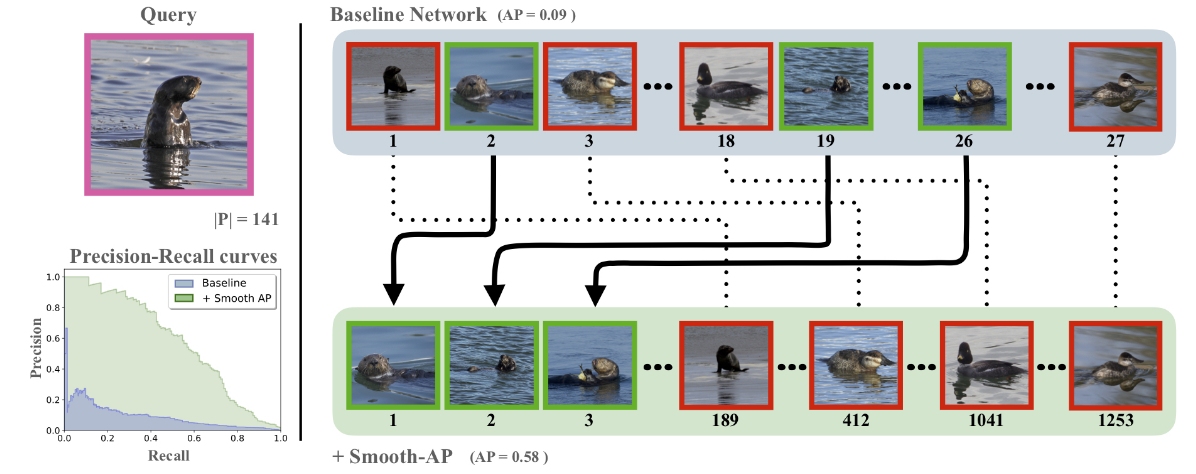
To solve this, the authors proposed to replace the Heaviside step function with a smooth temperature controlled sigmoid, making the ranking differentiable and useable as a loss function for end-to-end training. Compared to the triplet loss, the smooth-Ap loss optimizes a ranking loss, while the triplet loss is a surrogate loss that indirectly optimizes for a good ranking.
Hybrid Models for Open Set Recognition (paper)
Existing image classification methods are often based on a closed-set assumption, ie., the training set covers all possible classes that may appear in the testing phase. But this assumption is clearly unrealistic, given that even with large scale datasets such as ImageNet with 1K classes, it is impossible to cover all possible real-world classes. This where open-set classification comes, and tries to solves this by assuming that the test set contains both known and unknown classes.
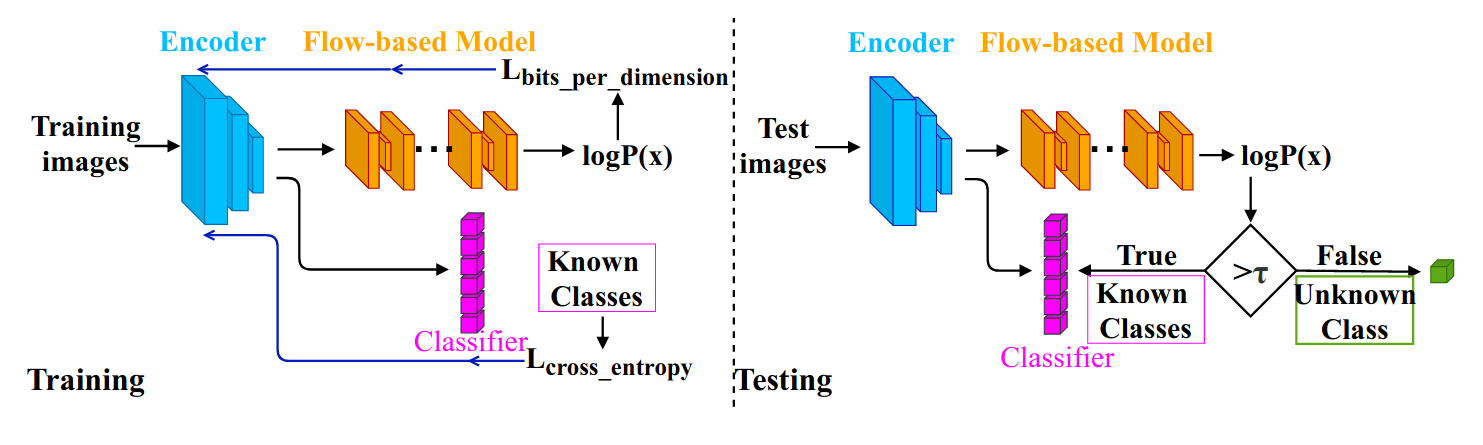
In this paper, the authors use Flow-based model to tackle the problem of open-set classification. Flow-based are able to fit a probability distribution to training samples in an unsupervised manner via maximum likelihood estimation. The flow model can then be used to predict the probability density of each example. When the probability density of an input sample is large, it is likely to be part of the training distribution with a known class, and outliers will have a small density value. While previous methods stacked a classifier on top of the flow model, the authors propose to learn a joint embedding for both the flow model and the classifier since the embedding space learned from only flow-based model may not have sufficient discriminative features for effective classification. As illustrated above, during training, images are mapped into a latent feature space by the encoder, then the encoded features are fed into both the classifier trained with a cross-entropy loss, and the flow model for density estimation. The whole architecture is trained in an end-to-end manner. For testing, the \(\log p(x)\) of each image is computed and then compared with the lowest \(\log p(x)\) taken over the training set. If it is greater than the threshold, it is sent to the classifier to identify its specific known class, otherwise it is rejected as an unknown sample.
Conditional Convolutions for Instance Segmentation (paper)
Instance segmentation remains as one of the challenging tasks in computer vision, requiring a per-pixel mask and a class label for each visible object in a given image. The dominant approach is Mask R-CNN which consists of two steps, first, the object detector Faster R-CNN predicts a bounding box for each instance. Then, for each detected instance, the regions of interest are cropped from the output feature maps using ROI Align, resized to the same resolution, and are then fed into a mask head which is a small fully convolutional network used to predict the segmentation mask. However, the authors point out the following limitation with such an architecture; (1) the ROI Align might fetch irrelevant features belonging to the background or to other instances, (2) the resizing operation restricts the resolution of the instance segmentation, and (3) the mask head requires a stack of 3x3 convolutions to induce a large enough receptive field to predict the mask, which considerably increases the computational requirements of the mask head.
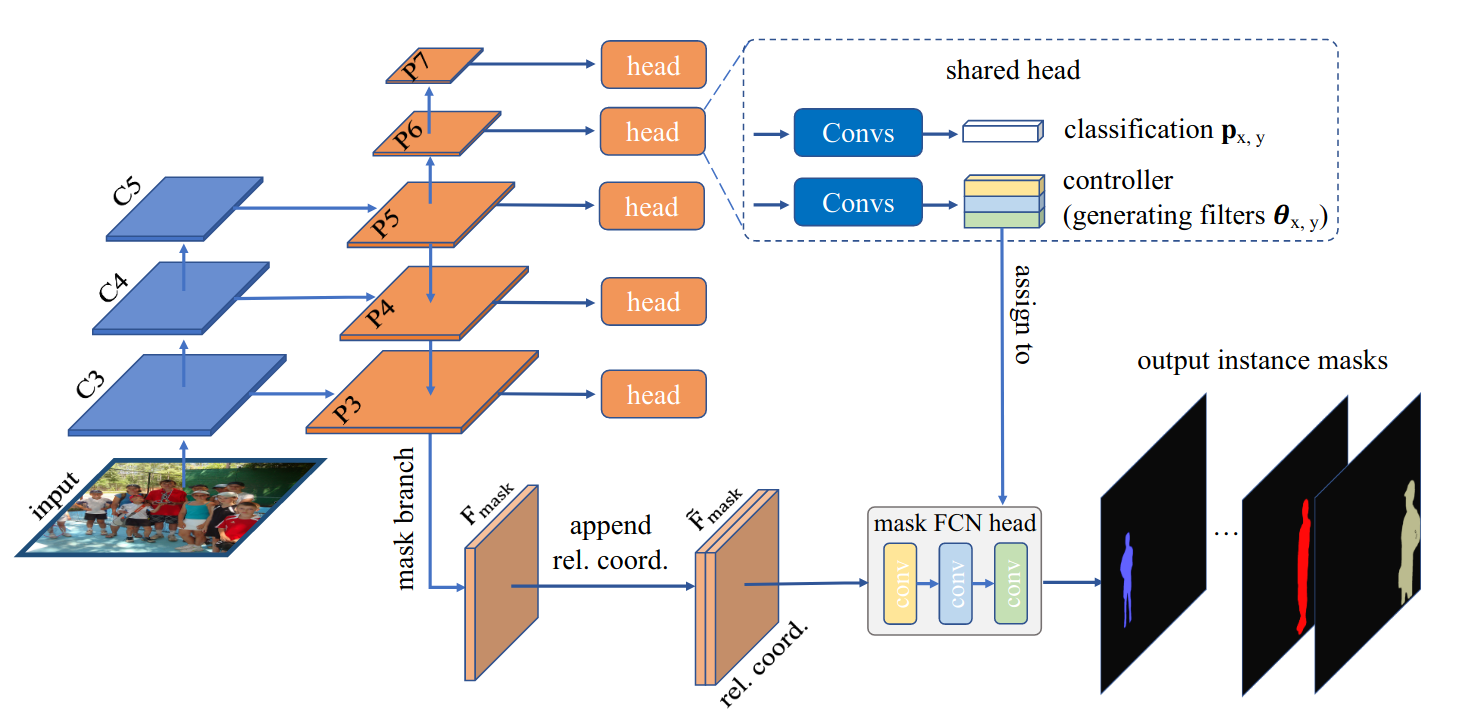
In this paper, the authors propose to adapt FCNs used for semantic segmentation for instance segmentation. For effective instance segmentation, FCNs require two type of information, appearance information to categorize objects and location information to distinguish multiple objects belonging to the same category. The proposed network, called CondInst (conditional convolutions for instance segmentation), is a network based on CondConv and HyperNetworks, where for each instance, a sub-network will generate the mask FCN head’s weights conditioned on the center area of each instance, which are then used to predict the mask of the given instance. Specifically, as shown above, the network consists of multiple heads applied at multiple scales of the feature map. Each head predicts the class of a given instance at pre-defined positions, and the network’s weights to be used by the mask FCN head. Then the mask prediction is done using the parameters produced by each head.
Multitask Learning Strengthens Adversarial Robustness (paper)
One of the main limitations of deep neural networks is their vulnerability to adversarial attacks, where very small and invisible perturbations are injected into the input, resulting in the wrong outputs, even if the appearance of the input remains the same. In recent years, the adversarial robustness of deep nets was rigorously investigated at different stages of the pipeline, from the input data (eg., using unlabeled data and adversarial training) to the model itself using regularization (eg., Parseval Networks), but the outputs of the model are still not utilized to improve the robustness of the model. In this paper, the authors investigate the effect of having multiple outputs for multi-task learning on the robustness of the learned model, such a setting is useful since a growing number of machine learning applications call for models capable of solving multiple tasks at once.
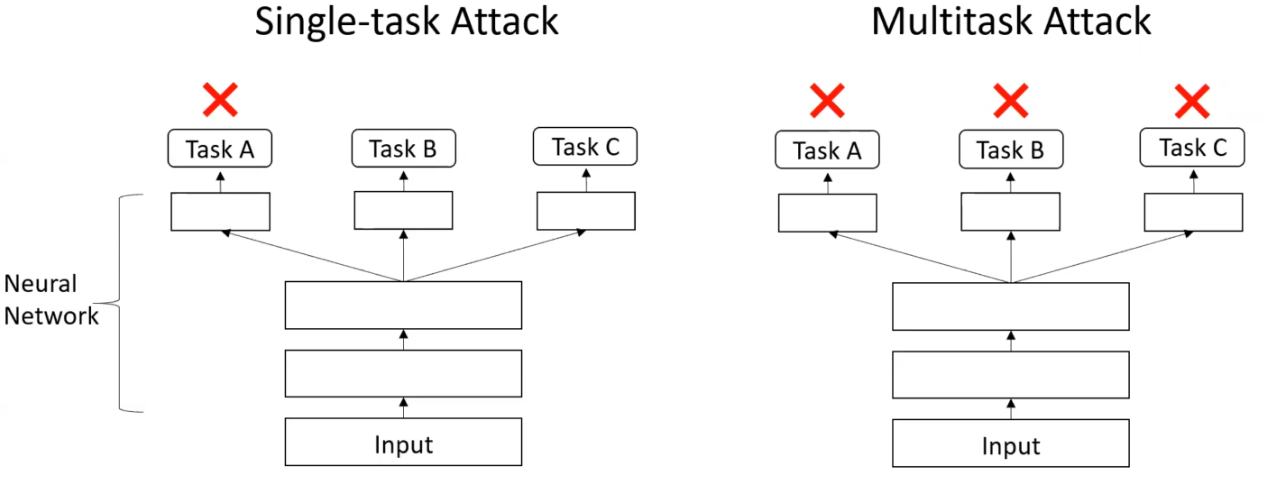
Using p-norm ball bounded attack, where the adversarial perturbation is found within a p-norm ball for a given radius of a given input example. Then, the vulnerability computed as the total loss change. The authors showed an improved robustness when training on a pair of tasks (eg., two tasks are chosen from: segmentation, depth, normals, reshading, input reconstruction, 2d and 3d keypoints…). The improved robustness is observed on single tasks attacks (ie., the perturbation is computed using one output) and multi tasks attacks (ie., the maximal perturbation of all the perturbations computed using all of outputs). The authors also theoretically showed that such a multi task robustness is only obtained if the tasks are correlated.
Dynamic Group Convolution for Accelerating Convolutional Neural Networks (paper)
Group convolutions were first introduced in AlexNet to accelerate training, and subsequently adapted for efficient CNNs such as MobileNet and Shufflenet. They consist of equally splitting the input and output channels in a convolution layer into mutually exclusive sections or groups while performing a normal convolution operation within each individual groups. So for \(G\) groups, the computation is reduced by \(G\) times. However, the authors argue that they introduce two key limitations: (1) they weaken the representation capability of the normal convolution by introducing sparse neuron connections, and (2) they have fixed channel division regardless of the properties of each input.
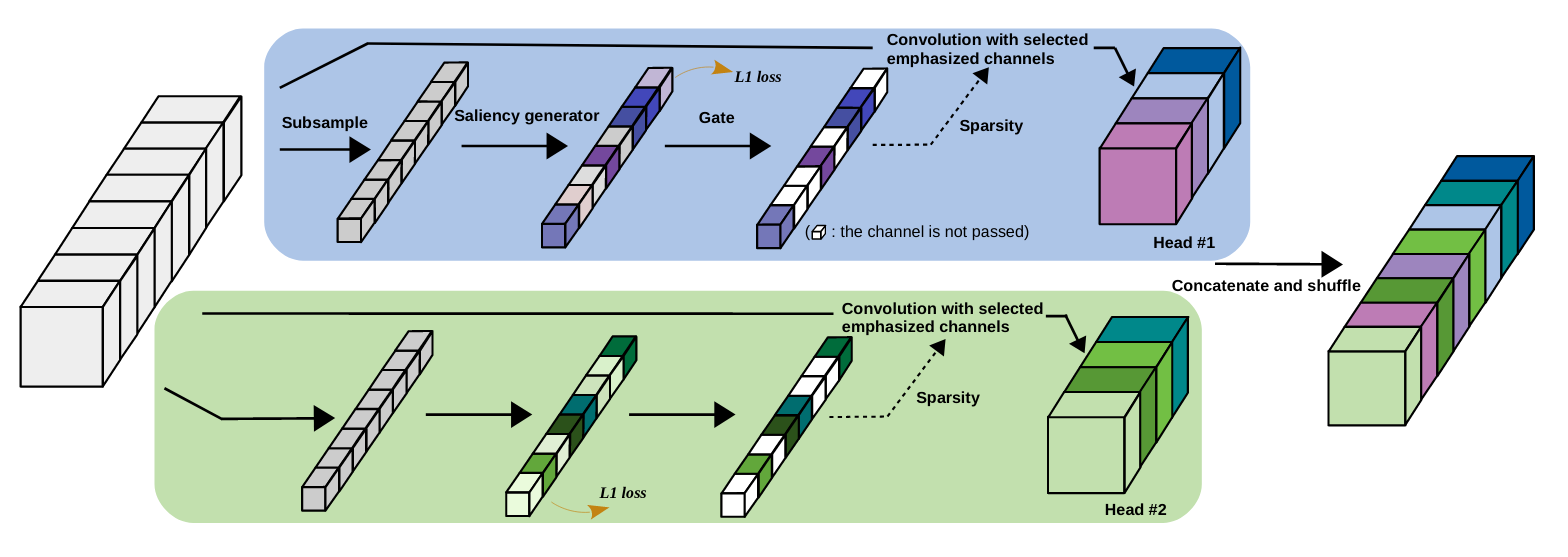
In order to adaptively select the most related input channels for each group while keeping the full structure of the original networks, the authors propose dynamic group convolution (DGC). DCG consists of two heads, in each head, there is a saliency score generator that assigns an importance score to each channel. Using these scores, the channels with low importance scores are pruned. Then the normal convolution is conducted based on the selected subset of input channels generating the output channels in each head. Finally, the output channels from different heads are concatenated and shuffled.
Disentangled Non-local Neural Networks (paper)
The non-local block models long-range dependency between pixels using the attention mechanism, and has been widely used for numerous visual recognition tasks, such as object detection, semantic segmentation, and video action recognition.
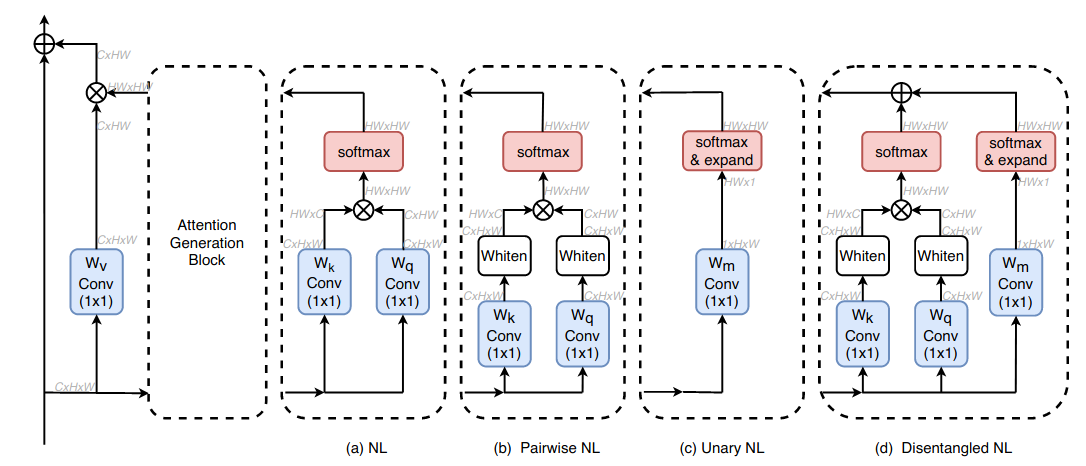
In this paper, the authors try to better understand the non-local block, find its limitations, and propose an improved version. First, they start by reformulating the similarity between a pixel \(i\) (referred to as a key pixel) to pixel \(j\) (referred to as a query pixel) as the sum of two term: a pairwise term, which is a whitened dot product term representing the pure pairwise relation between query and key pixels, and a unary term, representing where a given key pixel has the same impact on all query pixels. Then, to understand the impact of each term, they train using either one, and find that pair-wise term is responsible for the category information, while the unary is responsible for boundary information. However, by analyzing the gradient of the non-local block, when the two are combined in the normal attention operator, their gradients are multiplied, so if the gradients of one of the two term is zero, the non-zero gradients of the other wont have any contribution. To solve this, the authors proposed a disentangled version of the non-local, where each term is optimized separately.
Hard negative examples are hard, but useful (paper)
Deep metric learning optimizes an embedding function that maps semantically similar images to relatively nearby locations and maps semantically dissimilar images to distant locations. A popular way to learn the mapping is to define a loss function based on triplets of images: an anchor image, a positive image from the same class, and a negative image from a different class. The model is then penalized when the anchor is mapped closer to the negative image than it is to the positive image. However, during optimization, most triplet candidates already have the anchor much closer to the positive than the negative making them redundant. On the other hand, optimizing with the hardest negative examples leads to bad local minima in the early phase of the training. This is because in this case, the anchor-negative similarity is larger than the anchor-positive similarity as measured by the cosine similarity, ie., dot product between normalized feature vectors.
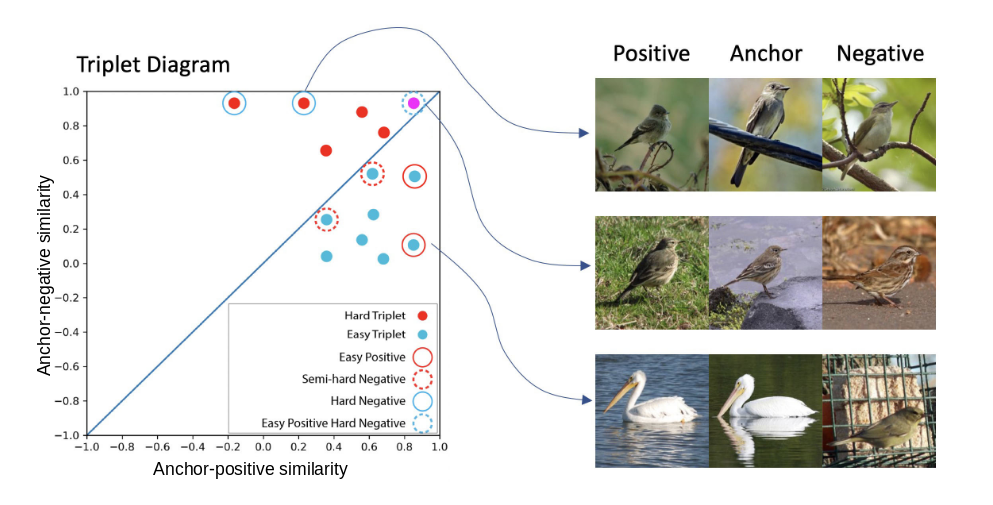
The authors show that such problems with the usage of hard-negatives come from the standard implementation of the triplet loss. Specifically, (1) if the normalization is not considered during the gradient computation, a large part of the gradient is lost, and (2) if two images of different classes are close by in the embedding space, the gradient of the loss might pull them closer instead of pushing them away. To solve this, instead of pulling the anchor-positive pair together to be tightly clustered as done in the standard triplet loss, the authors propose to avoid updating the anchor-positive pairs resulting in less tight clusters for a class of instances. This way the network focuses only on directly pushing apart the hard negative examples away from the anchor.
Volumetric Transformer Networks (paper)
One of the keys behind the success CNNs is their ability to learn discriminative feature representations of semantic object parts, which are very useful for computer vision tasks. However, CNNs still lacks the ability to handle various spatial variations, such as scale, view point and intra-class variations. Recent methods, such as spatial transformer networks (STNs), try to suppress such variations by first wrapping the feature maps of spatially different images to a standard canonical configuration, then train classifiers on such standard features. But such methods apply the same wrapping to all the feature channels, which does not take into consideration the fact that the individual feature channels can represent different semantic parts, which may require different spatial transformations with respect to the canonical configuration.
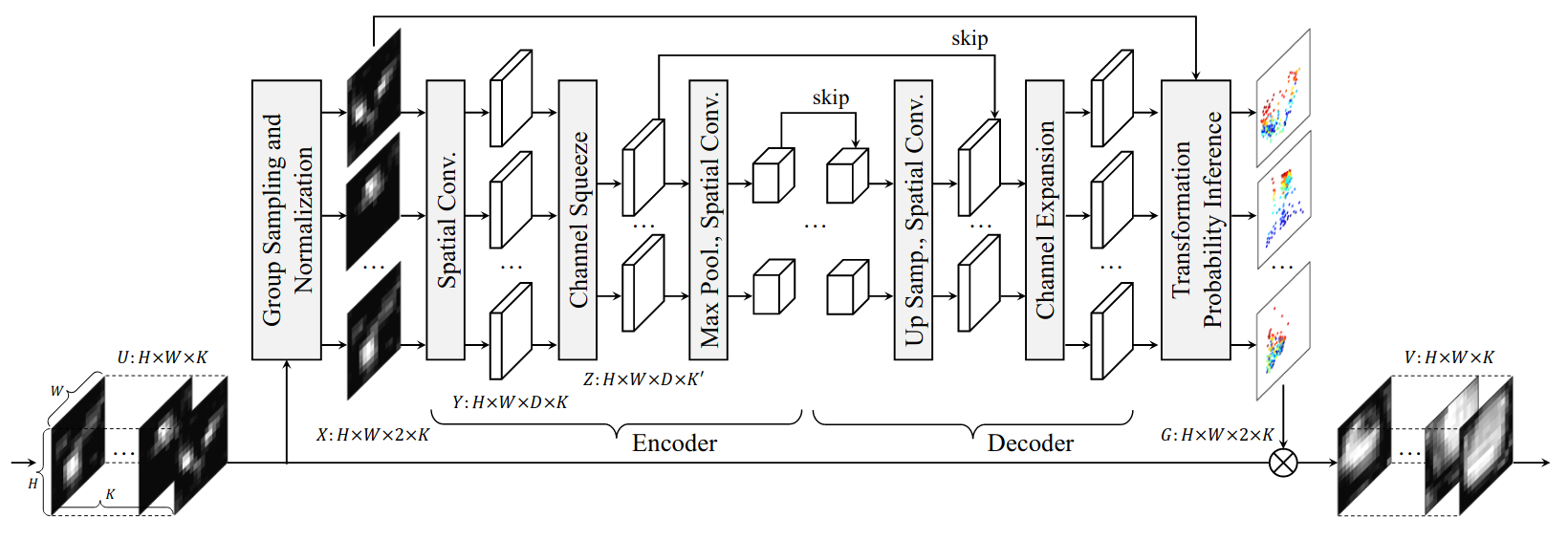
To solve this, the paper introduces Volumetric transformer network (VTN) shown above, a learnable module that predicts per channel and per spatial location wrapping transforms, which are used reconfigure the intermediate CNN features into a spatially agnostic and standard representations. VTN is an encoder-decoder network with modules dedicated to letting the information flow across the feature channels to account for the dependencies between the semantic parts.
Faster AutoAugment: Learning Augmentation Strategies Using Backpropagation (paper)
Data augmentations (DA) have become a important and indispensable component of deep learning methods, and recent works (eg., AutoAugment, Fast AutoAugment and RandAugment) showed that augmentation strategies found by search algorithms outperform standard augmentations. With a pre-defined set of possible transformations, such as geometric transformations like rotation or color enhancing transformations like solarization, the objective is to find the optimal data augmentation parameters, ie., the magnitude of the augmentation, the probability of applying it, and the number of transformations to combine as illustrated in the left figure below. The optimal strategy is learned with a double optimization loop, so that the validation error of a given CNN trained with a given strategy is minimized. However, such an optimization method suffers from a large search space of possible policies, requiring sophisticated search strategies, and a single iteration of policy optimization requires the full training of the CNN. To solve this, the authors propose to find the optimal strategy using density matching of original and augmented images with gradient based optimization.
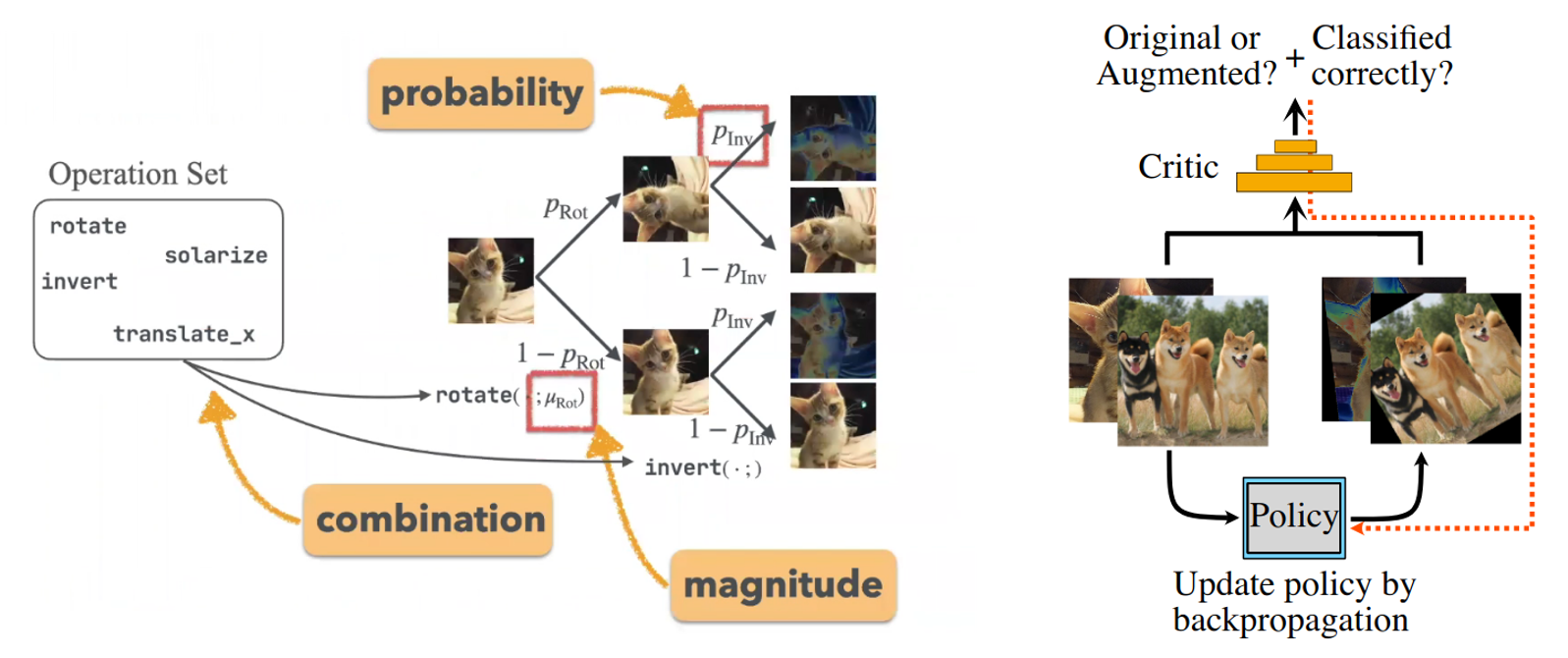
By viewing DA as a way to fill missing points of original data, the objective then is to minimize the distance between the distributions of augmented data and the original data using adversarial learning, and in order to learn the optimal augmentation strategy, the policy needs to be differentiable with respect to the parameters of the transformations. For the probability of applying a given augmentation, the authors use a stochastic binary variable sampled from a Bernoulli distribution, and optimized using the Gumbel trick, while the magnitude is approximate with a straight-through estimator and the combination are learned as a combination of one-hot vectors.
Other Papers
- Metric learning: cross-entropy vs. pairwise losses
- Semantic Flow for Fast and Accurate Scene Parsing
- Object-Contextual Representations for Semantic Segmentation
- Learning From Multiple Experts: Self-paced Knowledge Distillation for Long-tailed Classification
- Feature Normalized Knowledge Distillation for Image Classification
- Mixup Networks for Sample Interpolation via Cooperative Barycenter Learning
- OnlineAugment: Online Data Augmentation with Less Domain Knowledge
- Distribution-Balanced Loss for Multi-Label Classification in Long-Tailed Datasets
- DiVA: Diverse Visual Feature Aggregation for Deep Metric Learning
- Estimating People Flows to Better Count Them in Crowded Scenes
- SoundSpaces: Audio-Visual Navigation in 3D Environments
- Spatially Adaptive Inference with Stochastic Feature Sampling and Interpolation
- DADA: Differentiable Automatic Data Augmentation
- URIE: Universal Image Enhancement for Visual Recognition in the Wild
- BorderDet: Border Feature for Dense Object Detection
- TIDE: A General Toolbox for Understanding Errors in Object Detection
- AABO: Adaptive Anchor Box Optimization for Object Detection via Bayesian Sub-sampling
- PIoU Loss: Towards Accurate Oriented Object Detection in Complex Environments
- Learning Object Depth from Camera Motion and Video Object Segmentation
- Attentive Normalization
- Momentum Batch Normalization for Deep Learning with Small Batch Size
- A Simple Way to Make Neural Networks Robust Against Diverse Image Corruptions
Semi-Supervised, Unsupervised, Transfer, Representation & Few-Shot Learning
Big Transfer (BiT): General Visual Representation Learning (paper)
In this paper, the authors revisit the simple paradigm of transfer learning: pre-train on a large amount of labeled source data (e.g., JFT-300M and ImageNet-21k datasets), then fine-tune the per-trained weights on the target tasks, reducing both the amount of data needed for target tasks and the fine-tuning time. The proposed framework is BiT (Big Transfer), and consists of a number of components that are necessary to build an effective network capable of leveraging large scale datasets and learning general and transferable representations.
On the (upstream) pre-training side, BiT consists of the following:
- For very large datasets, the fact that Batch Norm (BN) uses statistics from the training data during testing results in train/test discrepancy, where the training loss is correctly optimized while the validation loss is very unstable. In addition to the sensitivity of BN to the batch size. To solve this, BiT uses both Group Norm and Weight Norm instead of Batch Norm.
- A small model such as ResNet 50 does not benefit from large scale training data, so the size of the model needs to also be correspondingly scaled up.
For (down-stream) target tasks, BiT proposes the following:
- The usage of standard SGD, withoyt any layer freezing, dropout, L2-regularization or any adaptation gradients. In addition to initializing the last prediction layer to all 0’s.
- Instead of resizing all of inputs to a fixed size, eg., 224. During training, the images are resized and cropped to a square with a randomly chosen size, and randomly h-flipped. At test time, the image is resized to a fixed size,
- While mixup is not useful for large scale pre-training given the abundance of data, BiT finds that mixup regularization can be very beneficial for mid-sized dataset used for downstream tasks.
Learning Visual Representations with Caption Annotations (paper)
Training deep models on large scale annotated dataset results in not only a good performance on the task at hand, but also enables the model to learn useful representation for downstream tasks. But can we obtain such useful features without such an expensive fine grained annotations?. This paper investigates weakly-supervised pre-training using noisy labels, which are image captions in this case.
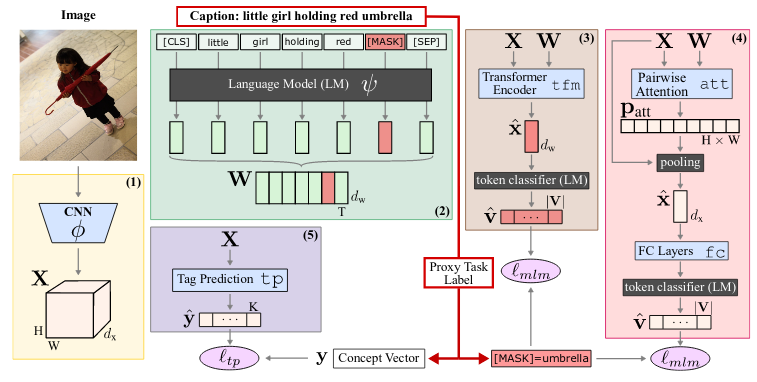
With the objective of using a limited set of image-caption pairs to learn visual representations, how can the training objective be formulated to push for an effective interaction between the images and their captions? Based on masked image modeling used in BERT which randomly masks 15% of the input tokens, and the model is then trained to reconstruct the masked input tokens using the encoder part of the transformer model. The paper proposed image-conditioned masked language modeling (ICMLM), where the images are leveraged to reconstruct the masked tokens of their corresponding captions. To solve this objective, the authors proposes two multi modal architectures, (1) ICMLM tfm, where the image is encoded using a CNN, the masked caption using the BERT model, the caption and image features are then concatenated and passed through a transformer encoder resulting in multi-modal embedding used to predict the masked token. And (2), ICMLM att+fc, similarity, the caption and image features are first produced, then passed through a pair-wise attention block to aggregate the information between the caption and the image. The resulting features are then pooled and passed through a fully connected layer for masked token prediction.
Memory-augmented Dense Predictive Coding for Video Representation Learning (paper)
The recent progress in self-supervised representation learning for images showed impressive results on down-stream tasks. However, although multi-model representation learning for videos saw similar gains, self-supervision using video streams only, without any other modalities such as text or audio, is still not as developed. Even if the temporal information of videos provide a free supervisory signal to train a model to predict the future states from the past in self-supervised manner. The task remains hard to solve since the exact future is not deterministic, and at a given time step, there many likely and plausible hypotheses for future states (eg., when the action is “playing golf”, a future frame could have the hands and golf club in many possible positions).
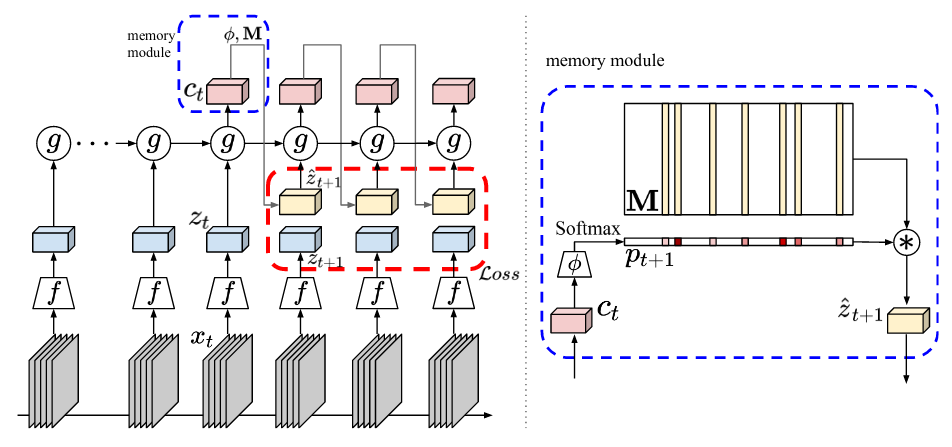
This paper uses contrastive learning with a memory module to solve the issues with future prediction. To reduce the uncertainty, the model predicts the future at the feature level, and is trained using a contrastive loss to avoid overstrict constrains. And to deal with multiple hypothesis, a memory module is used to infer multiple future states simultaneously. Given a set of successive frame, a 2d-3d CNN encoder (ie., \(f\)) produces context features and a GRU (ie., \(g\)) aggregates all the past information, which are then used to select slots from the shared memory module. A predicted future state is then produced as a convex combination of the selected memory slots. The predicted future state is then compared with true features vectors of the future states using a contrastive loss. For downstream tasks, the feature produced by \(g\) are pooled and then fed to the classifier.
SCAN: Learning to Classify Images without Labels (paper)
To group the unlabeled input images into semantically meaningful clusters, we need to find the solutions using the visual similarities alone. Prior work either, (1) learn rich features with a self-supervised method, then applies k-means on the features to find the cluster, but this can lead to degeneracy quite easily. (2) end-to-end clustering approaches that either leverage CNNs features for deep clustering, or are based on mutual information maximization. However, the produced clusters depend heavily on the initialization and is likely to latch into low-level features.
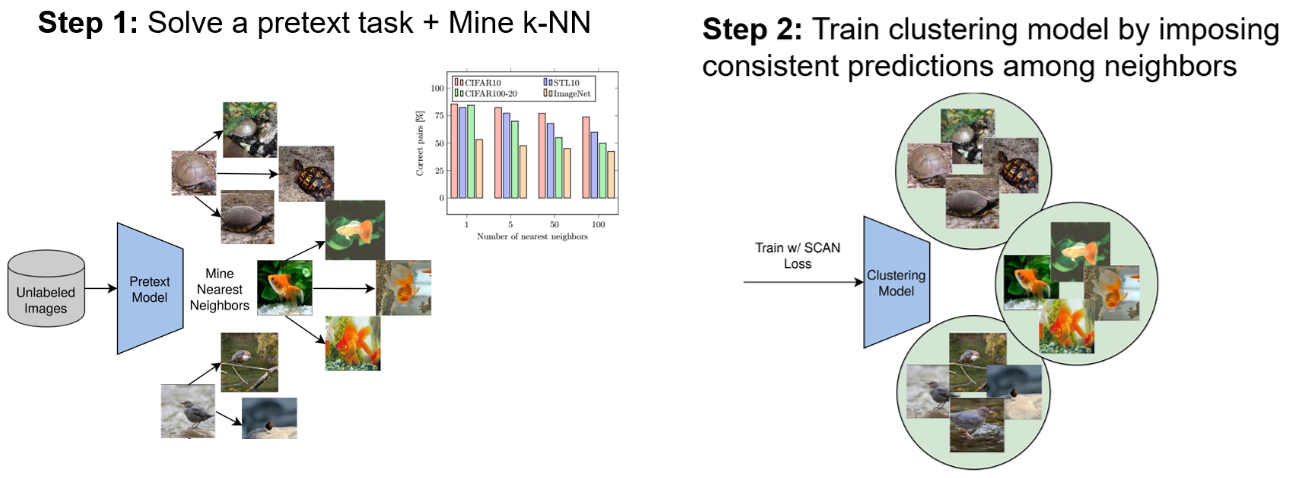
To solve the issues found in prior work, the paper proposes SCAN (semantic clustering by adopting nearest neighbors) consiting of a two step procedure. In a first step, the feature representations are learned through a pretext task, then, to generate the initial cluster, SCAN mines the nearest neighbors of each image based on feature similarity instead of applying K-means. In a second step, the semantically meaningful nearest neighbors as are used as a prior to train the model to classify each image and its mined neighbors together. This is optimized using a loss function that maximizes their dot product after softmax, pushing the network to produce both consistent and discriminative (one-hot) predictions.
GATCluster: Self-Supervised Gaussian-Attention Network for Image Clustering (paper)
Clustering consists of separating data into clusters according to sample similarity. Traditional methods use hand-crafted features and domain specific distance function to measure the similarity, but such hand crafted feature are very limited in expressiveness. Subsequent work leveraged deep representations with clustering algorithms, but the performance of deep clustering still suffers when the input data is complex. For an effective clustering, in terms of the features, they must contain both high-level discriminative features, and capture object semantics. In terms of the clustering step, trivial solutions such as assigning all samples to a single or few clusters must be avoided, and the clustering needs to be efficient to be applied to large-sized images.
The paper proposes GATCluster, which directly outputs semantic cluster labels without further post-processing, where the learned features are one-hot encoded vectors to guarantee the avoidance of trivial solutions. GATCluster is trained in an unsupervised manner with four self-learning tasks under the constraints of transformation invariance, separability maximization, entropy analysis, and attention mapping.
Associative Alignment for Few-shot Image Classification (paper)
In few-shot image classification, the objective is to produce a model that can learn to recognize novel image classes when very few training examples are available. One of the popular approaches is Meta-learning that extracts common knowledge from a large amount of labeled data containing the base classes, and used to train a model. The model is then trained to classify images from novel concepts with only a few examples. The meta objective is to find a good set of initial weights that converge rapidly when trained on the new concepts. Interestingly, recent works demonstrated that standard transfer learning without meta learning, where a feature extractor is first pre-trained on the base classes, then fine-tunes a classifier on top of the pre-trained extractor on the new few examples performs on par with more sophisticated meta-learning strategies. However, the freezing of the extractor during fine-tuning that is necessary to avoid overfilling hinders the performances.
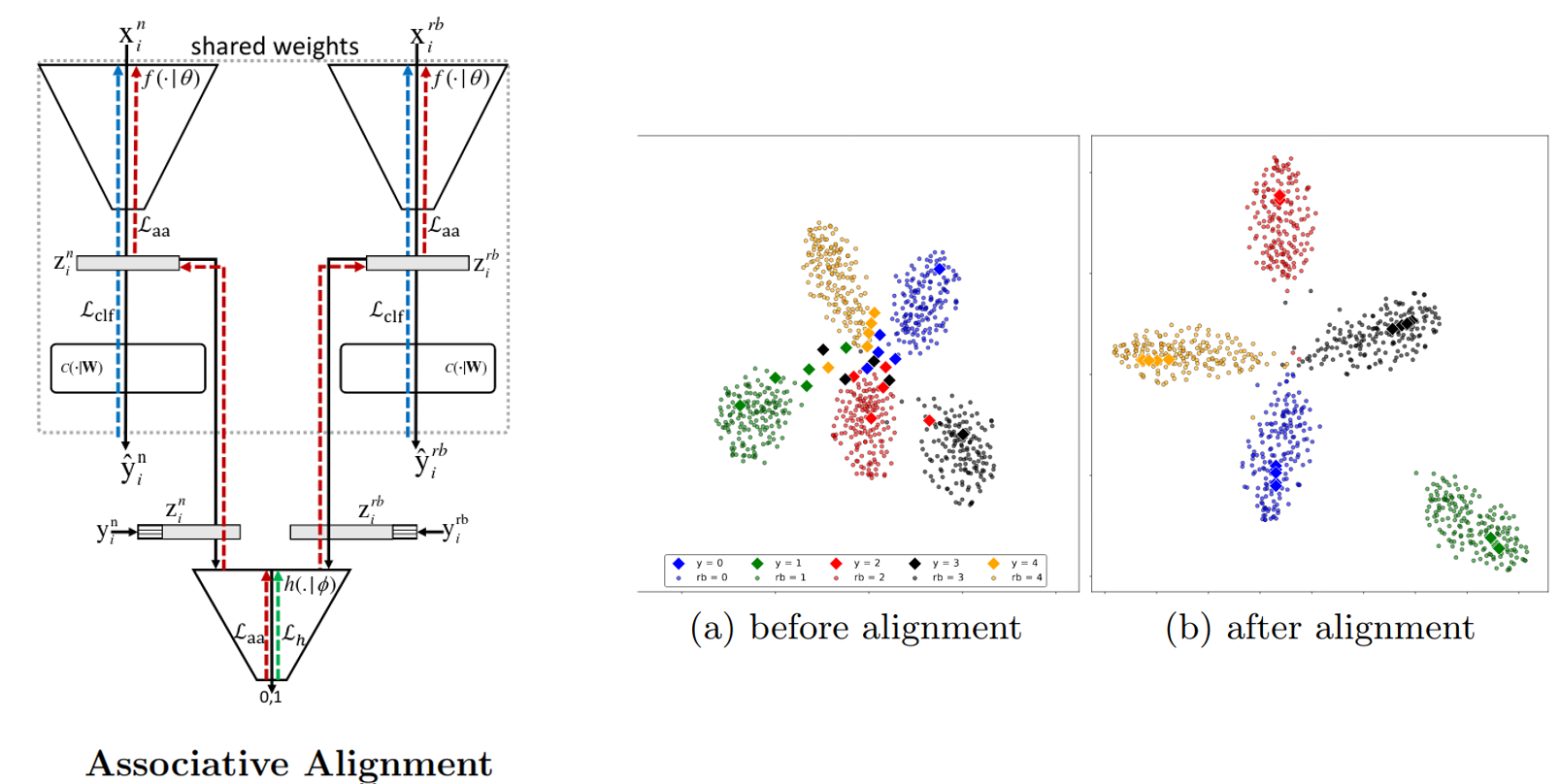
The paper proposes a two step approach to solve this. First, the feature extractor is used to produce features for the novel examples. The feature of each example is then mapped to one of the base classes using a similarity metric in the embeddings space. The second step consists of associative alignment, where the feature extractor is fine-tuned so that the embeddings of the novel images are pushed closer to the embeddings of their corresponding bases images. This is done by either centroid alignment where the distance between the center of each base class and the novel classes is reduced, or adversarial alignment where a discriminator pushes the feature extractor to align the base and novel examples in the embedding space.
Other Papers
- Domain Adaptation through Task Distillation
- Are Labels Necessary for Neural Architecture Search?
- The Hessian Penalty: A Weak Prior for Unsupervised Disentanglement
- Cross-Domain Cascaded Deep Translation
- Self-Challenging Improves Cross-Domain Generalization
- Label Propagation with Augmented Anchors for UDA
- Regularization with Latent Space Virtual Adversarial Training
- Transporting Labels via Hierarchical Optimal Transport for Semi-Supervised Learning
- Negative Margin Matters: Understanding Margin in Few-shot Classification
- Rethinking Few-Shot Image Classification: a Good Embedding Is All You Need?
- Prototype Rectification for Few-Shot Learning
3D Computer Vision & Robotics
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (paper)
3D view synthesis from 2D images is a challenging problem, especially if the input 2D images are sparsely sampled. The goal is to train a model that takes a set of 2D images of a 3D scene (with the optional camera pose and its intrinsics), then, using the trained model, we can render novel views of the 3D scene that were not found in the input 2D images. A successful approach is voxed-based representations that represent the 3D scene on a discredited grid. Anf the 3D voxel of RGB-alpha grid values is predicted using a 3D CNN. However, such methods are memory inefficient since they scale cubically with the space resolution, can be hard to optimize and are not able to parametrize scene surfaces smoothly. A recent trend in the computer vision community is to represent a given 3D scene as a continuous function using a fully-connected neural network. So the neural network itself is a compressed representation of the 3D scene, trained using the set of 2D images and then used to render novel views. Still, the existing methods were not able to match existing voxed-based methods.
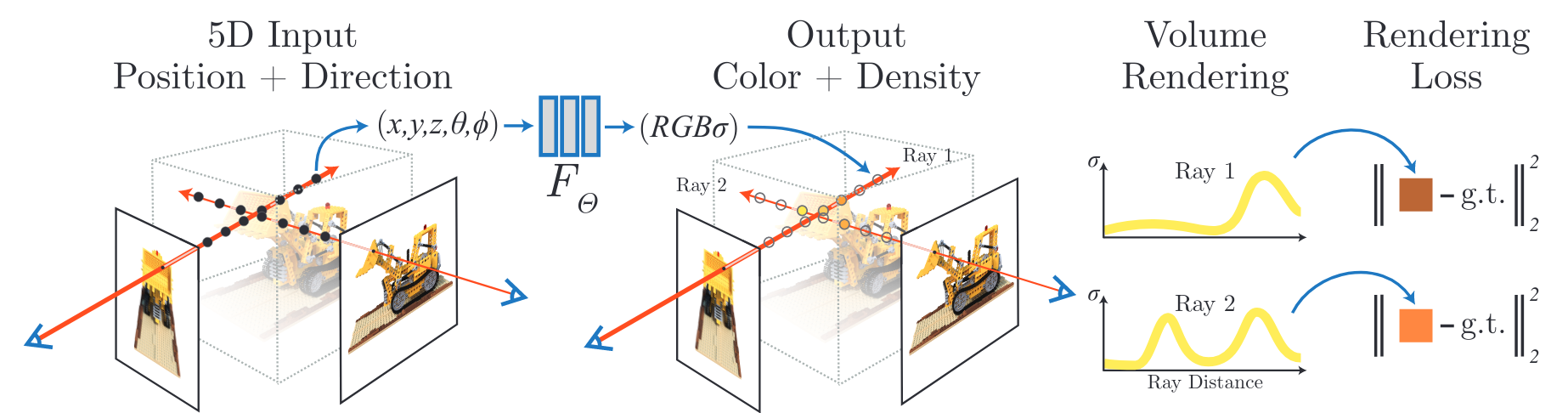
NeRF (neural radiance fields) represents a scene as a continuous 5D function using a fully-connected network of 9 layers and 256 channels, whose input is a single continuous 5D coordinate, ie., 3D spatial locations (\(x\), \(y\), \(z\)) and the viewing directions (\(\theta\), \(\phi\)), and whose output is RGB color and opacity (output density). To synthesize a given view, the rendering procedure consists of querying 5D coordinates along camera rays and use classic volume rendering techniques to project the output colors and densities into an image. Because volume rendering is naturally differentiable, the only input required to optimize the representation is a set of images with known camera poses. This way, NeRF is able to effectively optimize neural radiance fields to render photorealistic novel views of scenes with complicated geometry and appearance with a simple reconstruction loss between the rendered images and the ground truths, and demonstrates results that outperform prior work on neural rendering and view synthesis.
Towards Streaming Perception (paper)
Practical applications such as self-driving vehicles require fast reaction times similar to that of of humans, which is typically 200 milliseconds. In such settings, low-latency algorithms are required to ensure safe operation. However, even if the latency of computer vision algorithms is often studied, it have been primarily explored only in an offline setting. While Vision-for-online perception imposes quite different latency demands. Because by the time an algorithm finishes processing a particular image frame, say after 200ms, the surrounding world has changed as shown in the figure bellow. This forces the perception to be ultimately predictive of the future, which is a fundamental property of human vision (e.g., as required whenever a baseball player strikes a fast ball).
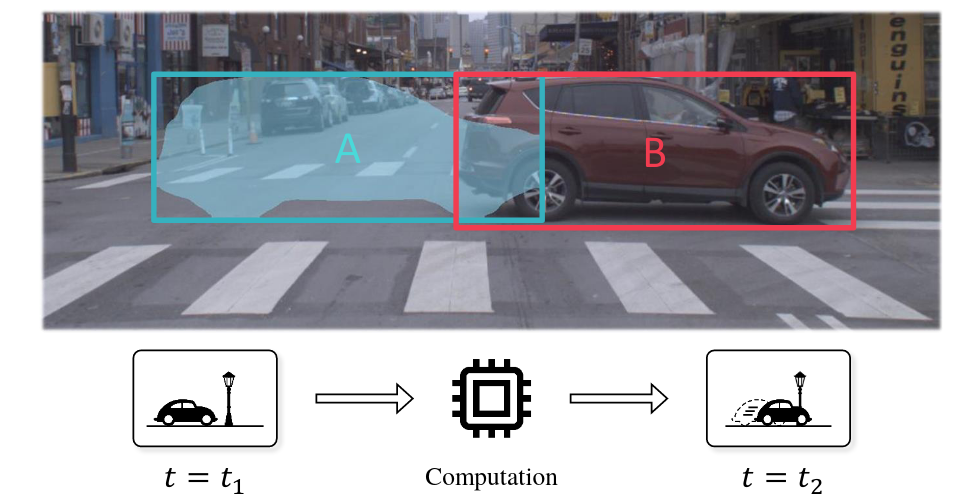
To develope better benchmarks that reflects real-world scenarios and make comparing existing method easier. The paper introduces the objective of streaming perception, ie., real-time online perception, and proposes a new meta-benchmark that systematically converts any image understanding task into a streaming image understand-ing task. This benchmark is built on a key insight: streaming perception requires understanding the state of the world at all time instants. So when a new frame arrives, streaming algorithms must report the state of the world even if they have not done processing the previous frame, forcing them to consider the amount of streaming data that should be ignored while the computation is occurring. Specifically, when comparing the model’s output and the ground truths, the alignment is done using time instead of the input index, so the model needs to give the correct prediction for time step \(t\) before the processing the corresponding input, ie., if the model takes \(\Delta t\) to process the inputs, it can only use data before \(t - \Delta t\) to predict the output corresponding to the input at time \(t\).
Teaching Cameras to Feel: Estimating Tactile Physical Properties of Surfaces From Images (paper)
Humans are capable of forming a mental model at a young age that maps the perception of an object with a perceived sense of touch, which is based on previous experiences when interacting with different items. Having autonomous agents equipped with such a mental model can be a very valuable tool when interacting with novel objects, especially when a simple object class is not informative enough to accurately estimate tactile physical properties.
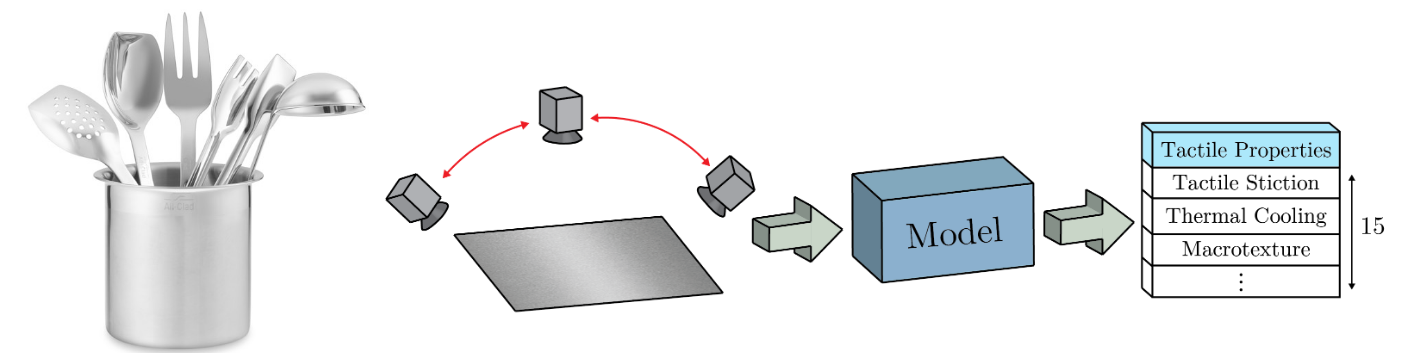
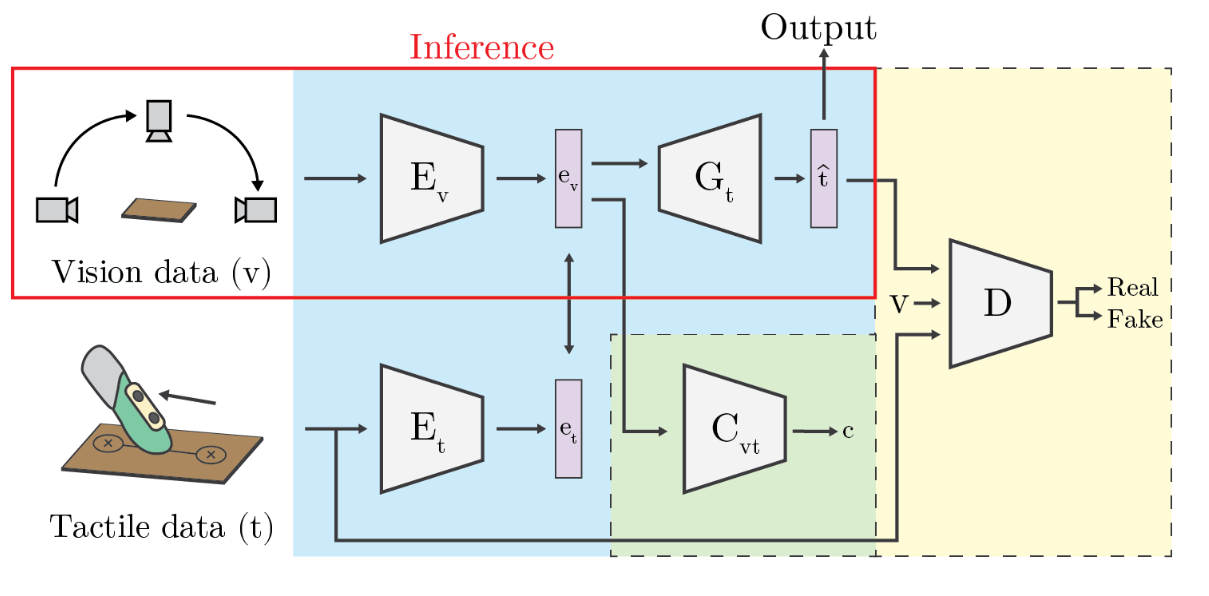
In order to simulate such a mental model in a more direct manner, the paper proposes to estimate the physical properties directly, allowing attributes of objects to be utilized directly. First, the authors propose a dataset of 400+ surface image sequences and tactile property measurements. Since when estimating surface properties, people often unconsciously move their heads, acquiring multiple views of a surface, the captured images sequences comprise multiple viewing angles for each material surface. Then, they propose a cross-modal framework for learning the complex mapping for visual cues to the tactile properties. The training objective of the model is to generate precise tactile properties estimates given vision information. Both visual and tactile information are embedded into a shared latent space through separate encoder networks. A generator function then estimates tactile property values from the embedded visual vector. The discriminator network learns to predict whether a tactile-visual pair is a real or synthetic example. During inference, the encoder-generator pair is used to infer the tactile properties if the input images.
Convolutional Occupancy Networks (paper)
3D reconstruction is an important problem in computer vision with numerous applications. For an ideal representation of 3D geometry we need to be able to, a) encode complex geometries and arbitrary topologies, b) scale to large scenes, c) encapsulate local and global information, and d) be tractable in terms of memory and computation. However, existing representations for 3D reconstruction do not satisfy all of these requirements. While recent implicit neural representation have demonstrated impressive performances in 3D reconstruction, they suffer from some limitation due to using a simple fully-connected network architecture which does not allow for integrating local information in the observations or incorporating inductive biases such as translational equivariance.
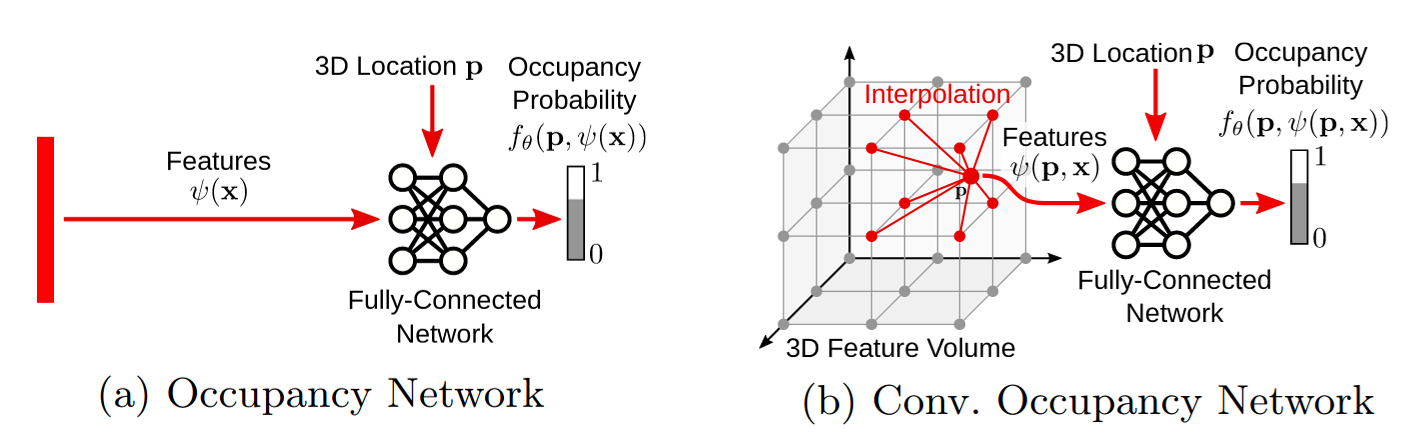
Convolutional Occupancy Networks uses convolutional encoders with implicit occupancy decoders to incorporates inductive biases and enabling structured reasoning in 3D space. Resulting in a more fine-grained implicit 3D reconstruction of single objects, with the ability to scale to large indoor scenes, and generalizes well from synthetic to real data.
Other Papers
- Tracking Emerges by Looking Around Static Scenes, with Neural 3D Mapping
- Privacy Preserving Structure-from-Motion
- Multiview Detection with Feature Perspective Transformation
- Motion Capture from Internet Videos
- Atlas: End-to-End 3D Scene Reconstruction from Posed Images
- Generative Sparse Detection Networks for 3D Single-shot Object Detection
- PointTriNet: Learned Triangulation of 3D Point Sets
- Points2Surf: Learning Implicit Surfaces from Point Cloud Patches
- Geometric Capsule Autoencoders for 3D Point Clouds
- Deep Feedback Inverse Problem Solver
- Single View Metrology in the Wild
- Shape and Viewpoint without Keypoints
- Hierarchical Kinematic Human Mesh Recovery
- 3D Human Shape and Pose from a Single Low-Resolution Image with Self-Supervised Learning
- Few-Shot Single-View 3D Object Reconstruction with Compositional Priors
- NASA: Neural Articulated Shape Approximation
- Hand-Transformer: Non-Autoregressive Structured Modeling for 3D Hand Pose Estimation
- Perceiving 3D Human-Object Spatial Arrangements from a Single Image in the Wild
Image and Video Synthesis
Transforming and Projecting Images into Class-conditional Generative Networks (paper)
GaNs are capable of generating diverse images from different classes. For instance, BigGaN, a class conditional GaN, given a noise vector \(z\) and a class embeddings \(c\), the model is capable of generating a new image from that class. The image can then be manipulated by editing the latent variable of the noise vectors and class embedding. But is the inverse possible?, ie., given an input image, can we find the latent variable \(z\) and the class embedding \(c\) that best matches to the image? This problem remains challenging since many input images cannot be generated by a GaN. Additionally, the objective function have many local minimas, the search algorithms can get stuck in such regions easily.
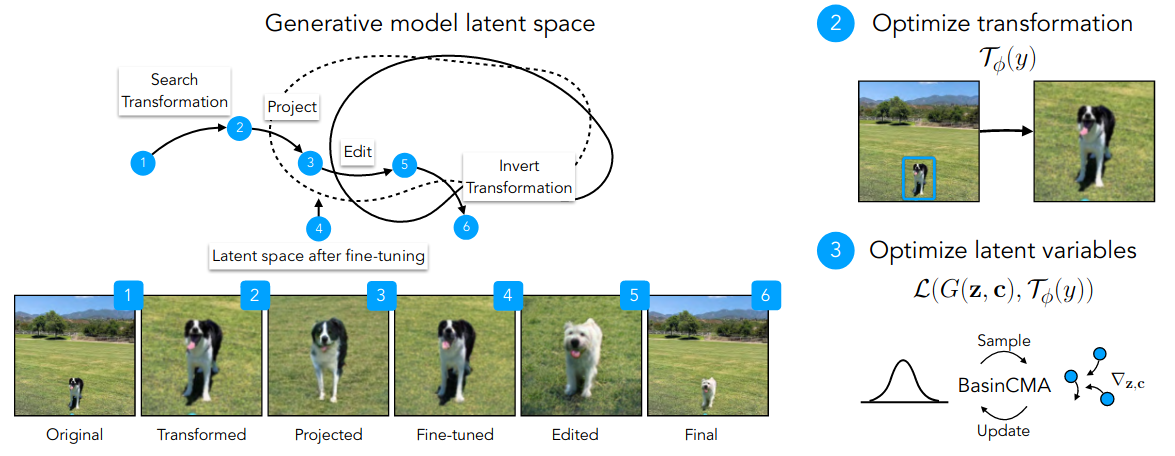
To address these problems, the paper proposes pix2latent with two new ideas: estimating input transformations at scale, and using a non-local search algorithm to find better solutions. As illustrated above, given an input image, pix2latent first finds the best transformation so that the transformed input is likely to be generated by a GaN, then the image is projected into the latent space using the proposed BasicCMA optimization method. The obtained latent variables are then edited, projected back into the image space obtaining an edited image, which can then be transformed with the inverse of the initial transformation
Contrastive Learning for Unpaired Image-to-Image Translation (paper)
Given two training sets of image pairs of different properties and modes, eg., images of horses and zebras, the objective of unpaired image-to-image translation is to learn a translation function between the two modes, eg., transform horses to zebras and vice-versa, while retaining the sensible information such as pose or size without having access to a set of one-to-one matches between the two modes. Existing methods such as CycleGaN forces the model to have back translated images that are consistent with the original ones. But such methods assume a bijection, which is often too restrictive since a given translated image might have many plausible source images. An ideal loss should be invariant to different styles, but differentiate between sensitive information.
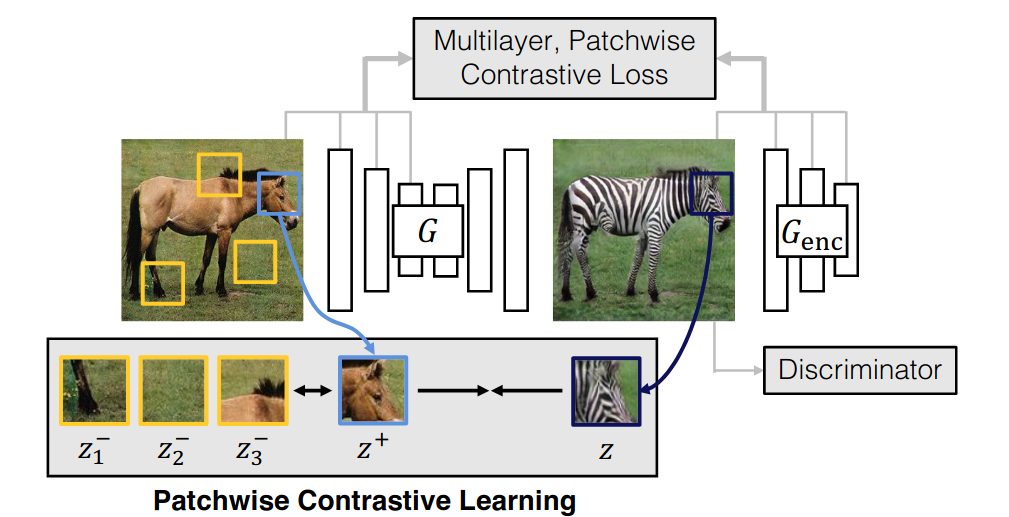
Contrastive Unpaired Translation (CUT) aims to learn such an embedding space. In addition to the standard GaN loss where the generator is trained to generate realistic translated images while the discriminator tries to differentiate between the translate images and real ones. An additional loss that pushes for similar embeddings between two corresponding patches from the input and translated image in used. Optimized with a contrastive objective which pulls the embeddings of the two corresponding patches, while pushing away the embedding of a give patch and its negatives which are randomly sampled patches (ie., only internal patches from the same input image are used, external ones from other images decrease the performances).
Rewriting a Deep Generative Model (paper)
GAN are capable of modeling a rich set of semantic and physical rules about the data distribution, but up to now, it has been obscure how such rules are encoded in the network, or how a rule could be changed. This paper introduces a new problem setting: manipulation of specific rules encoded by a deep generative model. So given a generative model, the objective is to adjust its weights, so that the new and modified model follows new rules, and generates images that follow the new set of rules as shown bellow.
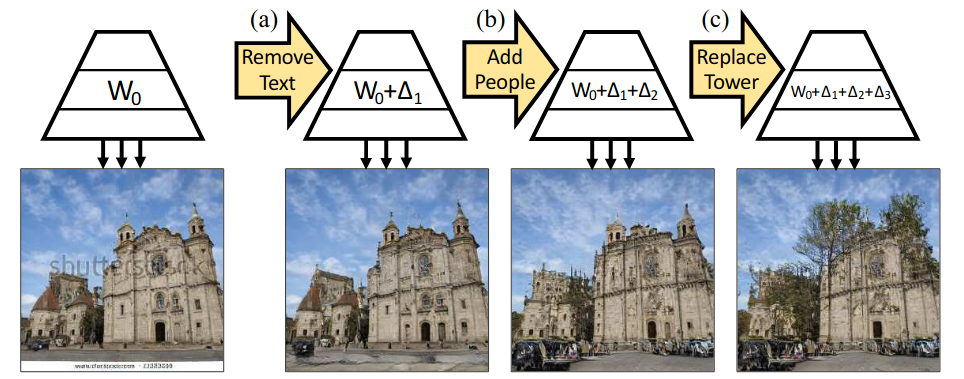
By viewing each layer as an associative memory that stores latent rules as a set of key-value relationships over hidden features. The model can be edited by defining a constrained optimization that adds or edits one specific rule within the associative memory while preserving the existing semantic relationships in the model as much as possible. The papers does this directly by measuring and manipulating the model’s internal structure, without requiring any new training data.
Learning Stereo from Single Images (paper)
Given a pair of corresponding images, the goal of stereo matching is to estimate the per-pixel horizontal displacement (i.e. disparity) between the corresponding location of every pixel from the first view to the second, or vice-versa. While fully supervised methods give good results, the precise ground truth disparity between a pair of stereo images is often hard to acquire. A possible alternative is to train on synthetic data, then fine-tune on a limited amount of real labeled data. But without a fine-tuning step with enough labels, such model are not capable of generating well to real images.
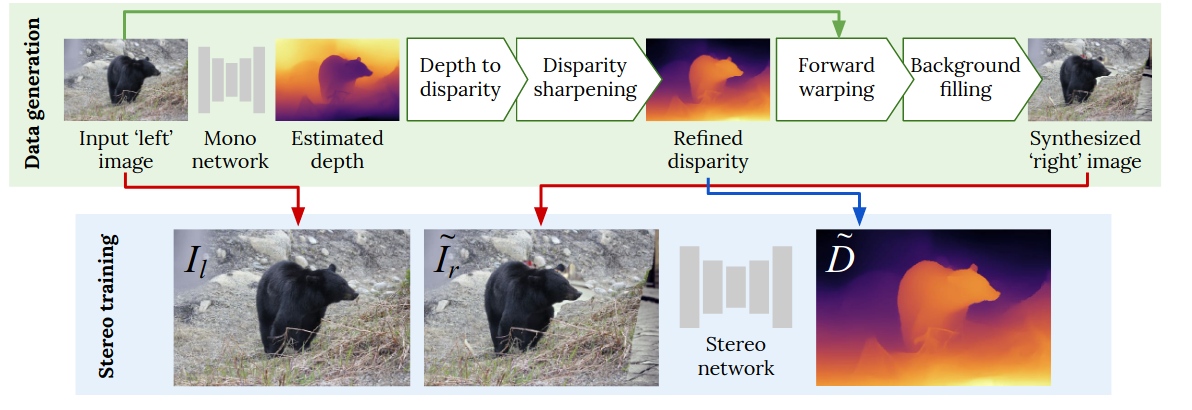
The paper proposed a novel and fully automatic pipeline for generating stereo training data from unstructured collections of single images given a depth-from-color model, requiring no synthetic data or stereo pairs of images to train. Using a depth estimation network. First, a given left input image is converted into a synthesized right image by a forward wrapping operation using the depth disparity. Then, with stereo pairs of images, the stereo network can then be trained in a supervised manner, resulting in a well generalizable model.
What makes fake images detectable? Understanding properties that generalize (paper)
Although the the quality of GaN generated images is reaching impressive levels, deep networks trained to detect fake images can still pick up on the subtle artifacts in these generated images, and such trained networks can also find the same artifacts across many models trained on different dataset and with different methods. This paper aims to visualize and understand which artifacts are shared between models and are easily detectable and transferable across different scenarios.

Since the global facial structure can vary among different generators and datasets, local patches of the generated images are more stereotyped and may share redundant artifacts. To this end, a fully-convolutional patch-based classifier is used to focus on local patches rather than global structure. The path level classifier can then be used to visualize and categorize the patches that are most indicative of real or fake images across various test datasets. Additionally, the generated image can be manipulated to exaggerate characteristic attributes of fake images.
Other Papers
- Free View Synthesis
- Unselfie: Translating Selfies to Neutral-pose Portraits in the Wild
- World-Consistent Video-to-Video Synthesis
- RetrieveGAN: Image Synthesis via Differentiable Patch Retrieval
- Generating Videos of Zero-Shot Compositions of Actions and Objects
- Perceiving 3D Human-Object Spatial Arrangements from a Single Image in the Wild
- Across Scales & Across Dimensions: Temporal Super-Resolution using Deep Internal Learning
- Conditional Entropy Coding for Efficient Video Compression
- Semantic View Synthesis
- Learning Camera-Aware Noise Models
- In-Domain GAN Inversion for Real Image Editing
Vision and Language
Connecting Vision and Language with Localized Narratives (paper)
One of the popular ways for connecting vision and language is image captioning, where each image is paired with human authored textual captions, but this link is only at the full image scale where the sentences describes the whole image. To improve this linking, grounded images captioning adds links between specific parts of the image caption and object boxes in the image. However, the links are still very sparse and the majority of objects and words are not grounded and the annotation process if expensive.

The paper proposes a new and efficient form of multi-modal image annotations for connecting vision and language called Localized Narratives. Localized Narratives are generated by asking the annotators to describe an image with their voice while simultaneously hovering their mouse over the region they are describing. For instance, as shown in the figure above, the annotator says “woman” while using their mouse to indicate her spatial extent, thus providing visual grounding for this noun. Later they move the mouse from the woman to the balloon following its string, saying “holding”. This provides direct visual grounding of this relation. They also describe attributes like “clear blue sky” and “light blue jeans”. Since voice is synchronized to the mouse pointer, the image location of every single word in the description can be determined. This provides dense visual grounding in the form of a mouse trace segment for each word. This rich from of annotation with multiple modalities (ie., image, text, speech and grounding) can be used to for different tasks such as text-to-image generation, visual question answering and voice-driven environnement navigation. Or for a more fine-grained control of tasks, such conditioning captions on specific parts of the image, which can be used by a person with imperfect vision to get descriptions of specific parts by hovering their finger on the image.
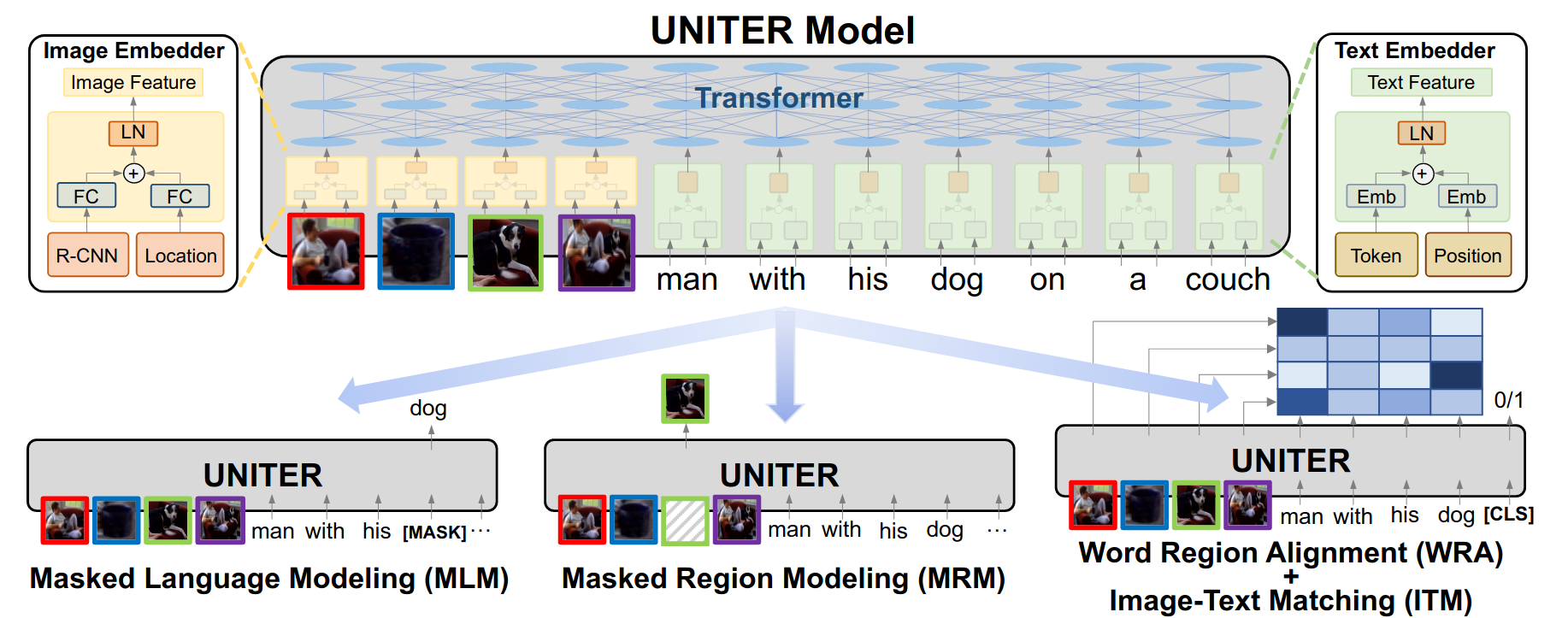
UNITER: UNiversal Image-TExt Representation Learning (paper)
Most Vision-and-Language (V&L) tasks such Visual Question Answering (VQA) rely on joint multi modal embeddings to bridge the semantic gap between visual and textual clues in images and text. But such representations are usually tailored for specific tasks, and require specific architectures. In order to learn general joint embeddings that can be used on all of the V&L downstream tasks. The paper introduces UNITER, a large-scale pre-trained model for joint multimodal embedding illustrated bellow. Based on the transformer model, UNITER is pre-trained on 4 tasks: Masked Language Modeling (MLM) conditioned on image, where the randomly masked words are recovered using both image and text features. Masked Region Modeling (MRM) conditioned on text, where the model reconstructs some regions of a given image. Image-Text Matching (ITM), where the model predicts if an image and a text instances are paired or not. And Word-Region Alignment (WRA), where the model learn the optimal alignment between words and images found using optimal transport. To use UNITER on downstream tasks, first they are reformulated as a classification problem, then the added classifier on top of the [CLS] features can be trained using a cross-entropy loss.
Learning to Learn Words from Visual Scenes (paper)
The standard approach in vision and language consists of learning a common embedding space, however this approach is inefficient, often requiring millions of examples to learn, generalizes poorly to the natural compositional structure of language, and the learned embeddings are unable to adapt to novel words at inference time. So instead of learning the word embeddings, this paper proposes to learn the process for acquiring word embeddings.
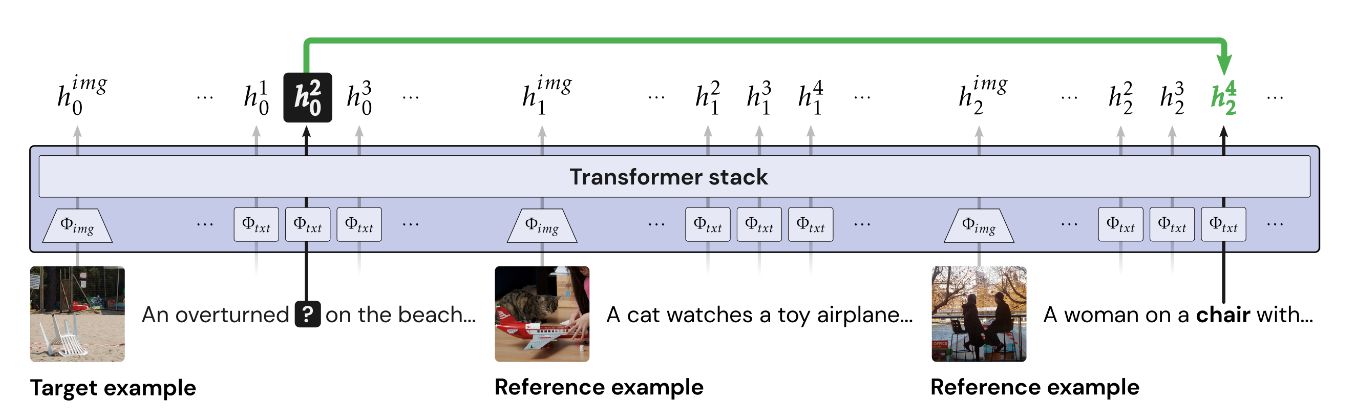
The model is based on the transformer model, and at each iteration, the model receives an episode of image and language pairs, and then meta-learns a policy to acquire word representations from the episode. This produces a representation that is able to acquire novel words at inference time as well as more robustly generalize to novel compositions. Specifically, every tasks is formulated as a language acquisition task or an episode, consisting of training examples and a testing examples, where the testing examples evaluates the language acquired from the training examples. In this figure above for instance, the model needs to acquire the word “chair” from the training samples, a word which it has never seen before. The meta-training is done in the forward pass, where the model needs to point to the correct word, “chair”, in the training example, and a matching loss is used to train the model. After training on many episodes and tasks, the model is able to adapt very quickly to novel task during inference.
Other Papers
- Contrastive Learning for Weakly Supervised Phrase Grounding
- Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments
- Adaptive Text Recognition through Visual Matching
The Rest
Unfortunately, the number of papers makes the summarization task difficult and time consuming. So for the rest of the papers, I will simply list some papers I came across in case the the reader is interested in the subjects.
Click to expand
Deep Learning: Applications, Methodology, and Theory:
- A Generic Visualization Approach for Convolutional Neural Networks
- Spike-FlowNet: Event-based Optical Flow Estimation
- A Metric Learning Reality Check
- Learning Predictive Models from Observation and Interaction
- Beyond Fixed Grid: Learning Geometric Image Representation with a Deformable Grid
- Stable Low-rank Tensor Decomposition for Compression of Convolutional Neural Network
- EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning
- Making Sense of CNNs: Interpreting Deep Representations & Their Invariances with INNs
- Event-based Asynchronous Sparse Convolutional Networks
Low level vision, Motion and Tracking:
- RAFT: recurrent all pairs field transforms for optical flow
- VisualEchoes: Spatial Image Representation Learning through Echolocation
- Self-Supervised Learning of Audio-Visual Objects from Video
- Tracking Objects as Points
Face, Gesture, and Body Pose:
- Style Transfer for Co-Speech Gesture Animation: A Multi-Speaker Conditional-Mixture Approach
- Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues
- Lifespan Age Transformation Synthesis
- Monocular Expressive Body Regression through Body-Driven Attention
- DLow: Diversifying Latent Flows for Diverse Human Motion Prediction
- Fast Bi-layer Neural Synthesis of One-Shot Realistic Head Avatars
- Blind Face Restoration via Deep Multi-scale Component Dictionaries
Action Recognition, Understanding:
- RubiksNet: Learnable 3D-Shift for Efficient Video Action Recognition
- Self-supervised Video Representation Learning by Pace Prediction
- Aligning Videos in Space and Time
- Forecasting Human-Object Interaction: Joint Prediction of Motor Attention and Actions in First Person Video
- Foley Music: Learning to Generate Music from Videos