The 2021 CVPR conference, one of the main computer vision and machine learning conferences, concluded its second 100% virtual version last week with a record of papers presented at the main conference. Of about 7500 submissions, 5900 made it to the decision making process and 1660 papers (vs 1467 papers last year) were accepted with an acceptance rate of 23.7% (vs 22.1% last year). Such a huge (and growing) number of papers can be a bit overwhelming, so to get a feel of the general trends at the conference this year, I will present in this blog post a quick look of the conference by summarizing some papers (& listing some) that seemed interesting to me.
First, let’s start with some useful links:
- Papers: CVPR2021 open access
- Workshops: CVPR2021 workshops
- Tutorials: CVPR2021 tutorials
- Presentations: Crossminds
- Papers search interface: blog.kitware.com & public.tableau.com
- Awards: CVPR2021 paper awards
- Papers digest: CVPR2021 Paper Digest
- Papers & code: CVPR2021 paper & code
Note: This post is not an objective representation of the papers and subjects presented in CVPR 2021, it is just a personnel overview of what I found interesting. Any feedback is welcomed!
Table of Contents
- CVPR 2021 in numbers
- Recognition, Detection & Tracking
- Model Architectures & Learning Methods
- 3D Computer Vision
- Image and Video Synthesis
- Scene Analysis & Understanding
- Representation & Adversarial Learning
- Transfer, Low-shot, Semi & Unsupervised Learning
- Computational Photography
- Other Subjects
CVPR 2021 in numbers
A portion of the statistics presented in this section are taken from this github repo & this public tableau gallery.
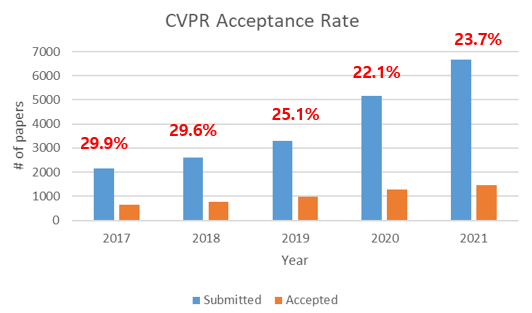
The trends of earlier years continued with a notable increase in authors and number of submitted papers, joined by a rising the number of reviewers and area chairs to accommodate this expansion.
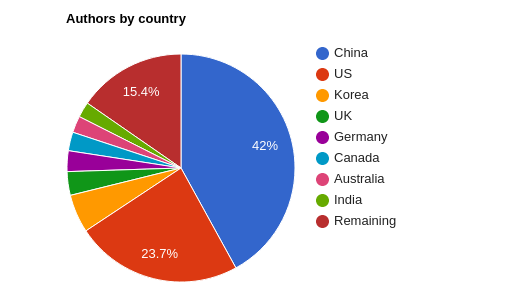
Similar to the last two years, China is the first contributor to CVPR in terms of accepted papers, followed by the USA, Korea, UK and Germany.
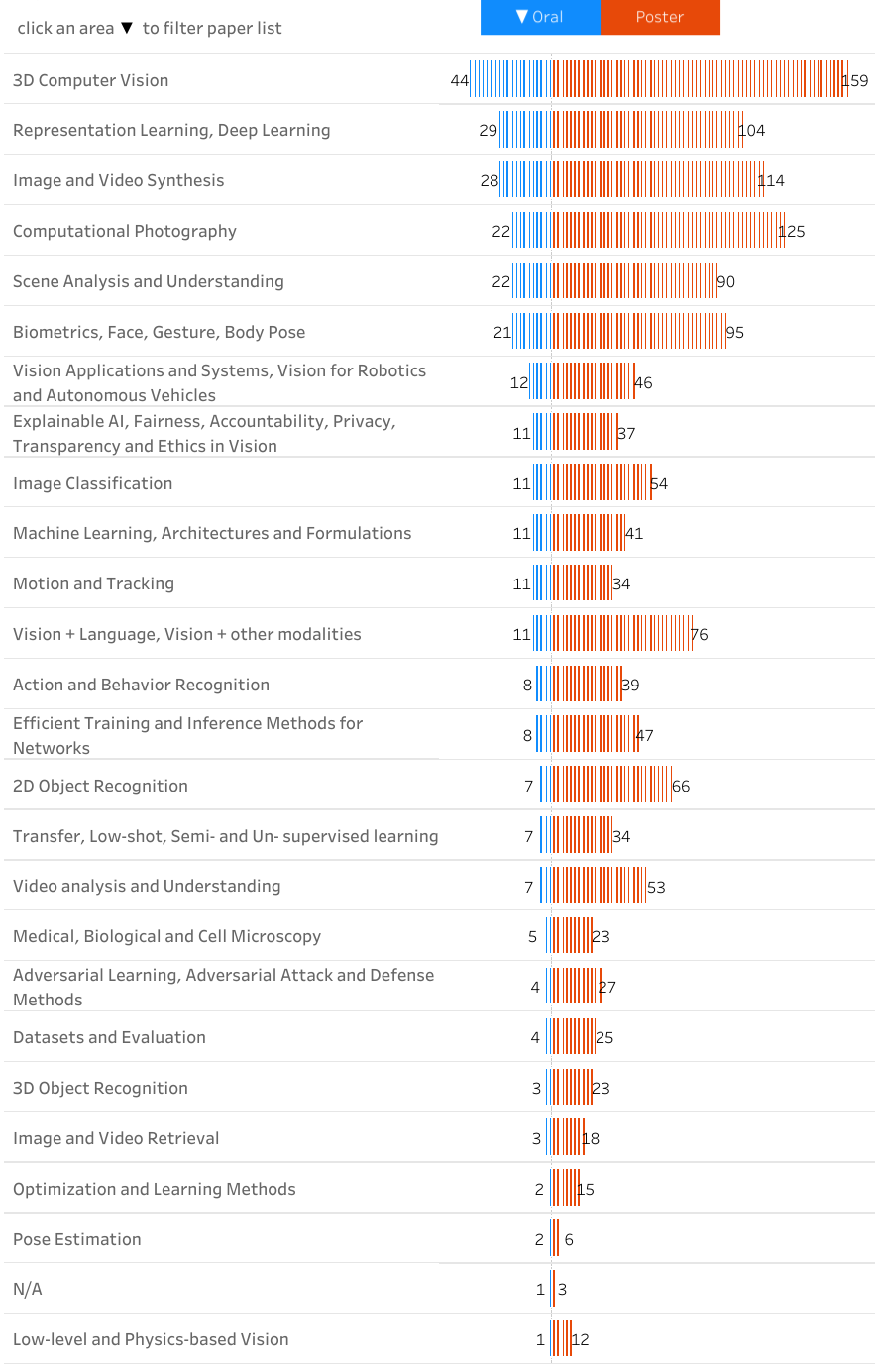
As expected, the majority of the accepted papers focus on topics related to learning, recognition, detection, and understanding. However, the topic of the year is 3D computer vision with more than 200 papers focusing on this subject alone, followed by deep & representation learning, image synthesis, and computation photography. There is also a notable increase in papers related to explainable AI and medical & biological imaging.
Recognition, Detection & Tracking
Task Programming: Learning Data Efficient Behavior Representations (paper)

In behavioral analysis, the location and pose of agents is first extracted from each frame of a behavior video, and then the labels are generated for a given set of behaviors of interest on a frame-by-frame basis based on the pose and movements of the agents as depicted in the figure above. However, to predict the behaviors frame-by-frame in the second step, we need to train behavior detection models which are data intensive and require specialized domain knowledge and high-frequency temporal annotations. This paper studies two alternative ways to better use domain experts instead of a simple increase in the number of annotations: (1) self-supervised learning and (2) creating task programs by domain experts which are engineered decoder tasks for representation learning.
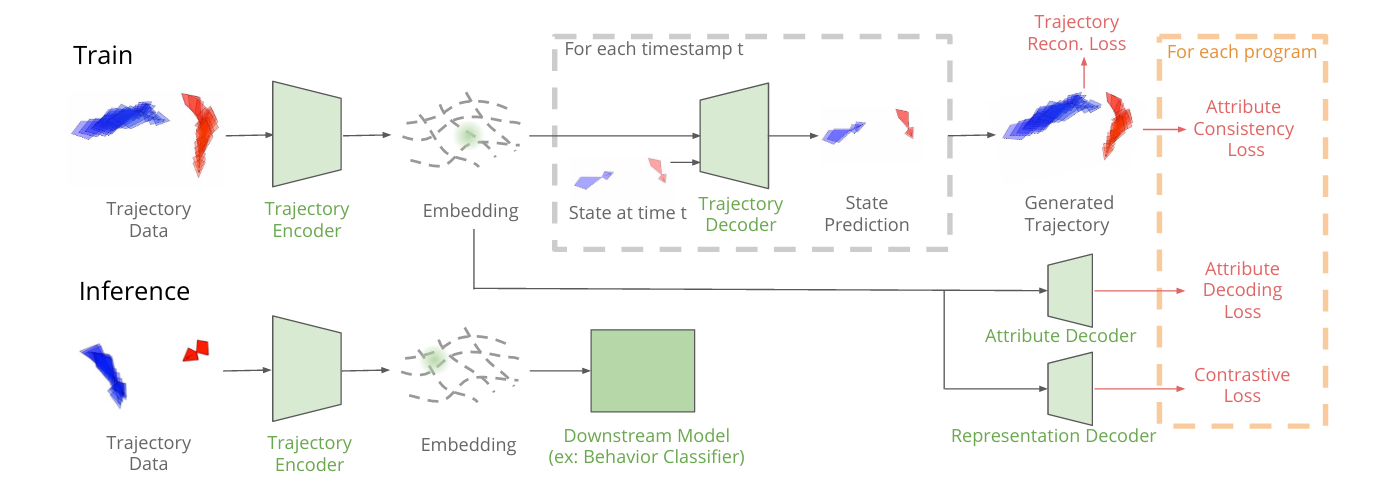
Trajectory Embedding for Behavior Analysis (TREBA) uses these two ideas to learn task-relevant low-dimensional representations of pose trajectories, this is done by training a network to jointly reconstruct the input trajectory and predict the expert-programmed decoder tasks (see figure above). For the first task, given a set of unlabelled trajectories, where each trajectory is a sequence of states (eg, location or pose of the agents), the history of the agent stages is encoded using an RNN encoder, and the RNN the decoder (ie, a trajectory variational autoencoder or TVAE) then predicts the next states. As for the second task, we first need to create decoder tasks for trajectory self-supervised learning by domain experts (which is called the process of Task Programing). First, the experts find the attributes from the trajectory data that are useful to detect the agents behaviors of interest, then write a program to compute these attributes (eg, distance or angle between two interacting mice) based on the trajectory data using systems like MARS or SimBA. These programs are finally used to generate training data for self-supervised multi-task learning.
Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks (paper)
One of the main challenges of deploying deep nets on mobile and low-power computational platforms for large scale usage is their large memory and computational requirements. Luckily, such deep nets are often overparameterized, living some room for compression to reduce their memory and computational demands wit a minimal accuracy hit. One way to compress deep nets is scalar quantization, which compresses each parameter individually, but the compression rates are still limited by the number of parameters. Another approach is vector quantization which compresses multiple parameters into a single code, thus exploiting redundancies among groups of network parameters, but finding the parameters to group can be challenging (eg, in fully connected layers for example, there is no notion of spatial dimensions to group the parameters by).

The paper proposes Permute, Quantize, and Fine-tune (PQF), a method that (1) searches for permutations of the network weights that yield functionally equivalent, yet an easier-to-quantize network, (2) quantizes the permuted weights, and finally, (3) fine tunes the permuted-and-quantized network to recover the accuracy of the original uncompressed network. Since the second step consists splitting each weight matrix \(W\) into subvectors (say \(d\) elements per subvector) which are then compressed individually, where each subvector is approximated by a smaller code or centroid, the objective of the first step is to find a permutation \(P\) of the weight matrix such that the constructed subvectors are easier to quantize into codes (see figure above). The optimization of \(P\) is done by minimizing the determinant of the covariance of the resulting subvectors (see the paper for why they do this). Finally, a fine tuning of the compressed network is conducted to remove the accumulated errors in the activations after the quantization which degrade the performances.
Towards Open World Object Detection (paper)
In this work, the authors propose a novel computer vision problem called Open World Object Detection, where a model is trained to: 1) identify objects that have not been introduced to it as unknown without explicit supervision to do so (ie, open set learning), and 2) incrementally learn these identified unknown categories without forgetting previously learned classes when the corresponding labels are progressively received (ie, incremental and continual learning). In open set recognition, the objective is to identify the new instances not seen during training as unknowns, while open world recognition extends this framework by requiring the classifier to recognize the newly identified unknown classes. However, adapting the open set and open world methods from recognition to detection is not trivial since the object detector is explicitly trained to detect the unknown classes as background, making the task of detecting unknown classes harder.
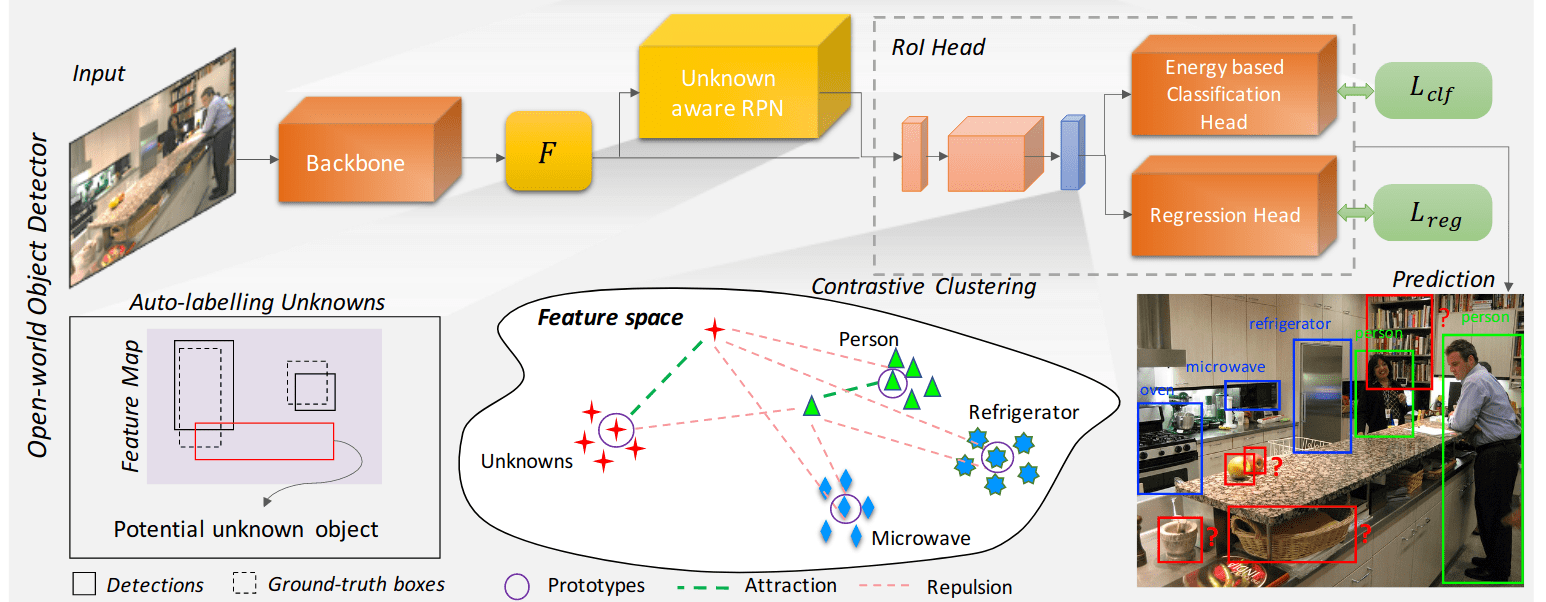
To solve this problem, the paper proposes ORE, Open World Object Detector, that learns a clear discrimination between classes in the latent space. This way, (1) the task of detecting an unknown instance as a novelty can be reduced to comparing its representation with the representations of the known instances (ie, open set detection), and also (2), it facilitates learning feature representations for the new class instances without overlapping with the previous classes (ie, incremental and continual learning, thus extending open set to open world detection). To have such a learning behavior, a contrastive clustering objective is introduced in order to force instances of same class to remain close-by, while instances of dissimilar classes would be pushed far apart. This is done by minimizing the distances between the class prototypes and the class representations, where the instances of class unknown are instances with high objectness score, but do not overlap with a ground-truth objects. The classification head of the trained detector is then transformed into an energy function to label an instance as unknown or not.
Learning Calibrated Medical Image Segmentation via Multi-Rater Agreement Modeling (paper)
For a standard vision task, it is a common practice to adopt the ground-truth labels obtained via either the majority-vote or by simply one annotation from a preferred rater as the single source of the training data. However, in medical images, the typical practice consists of collecting multiple annotations, each from a different clinical expert or rater, in the expectation that possible diagnostic errors could be mitigated. In this case, using standard training procedure of other vision tasks will overlook the rich information of agreement or disagreement ingrained in the raw multi-rater annotations available in medical image analysis. To take this into consideration, the paper proposes MR-Net to explicitly model the multi-rater agreement or disagreement.
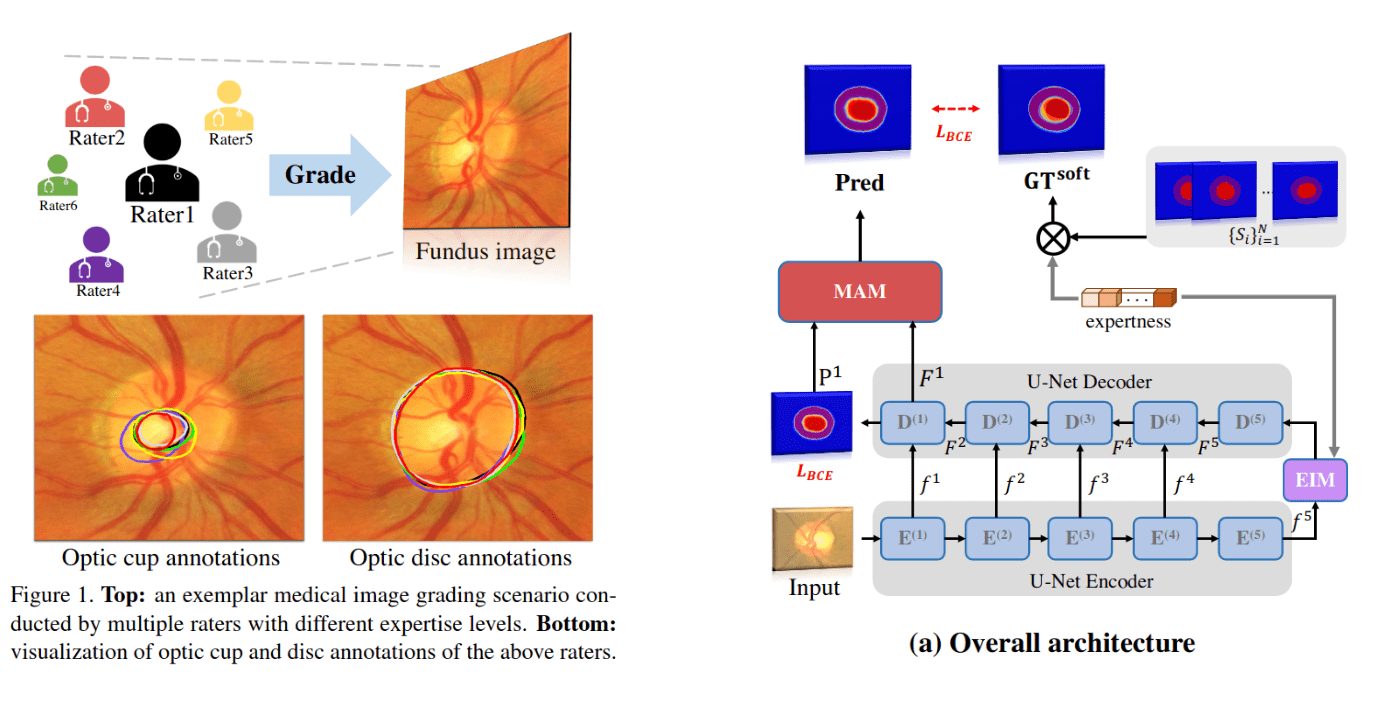
MRNet contains a coarse to fine two-stage processing pipeline (figure above, right). The first stage consists of a U-Net encoder with a ResNet34 backbone pretrained on ImageNet. Together with an Expertise-aware Inferring Module (EIM), inserted at the bottleneck layer to embed the expertise information of individual raters, named expertness vector, into the extracted high-level semantic features of the network. The outputs are then passed to the U-Net decoder to give a coarse prediction. The second stage then refines the coarse predictions using two modules. The first one is Multi-rater Reconstruction Module (MRM) that reconstructs the raw multi-rater’s grading, the reconstructions are then used to estimate the pixel-wise uncertainty map that represents the inter-observer variability across different regions. Finally, a Multi-rater Perception Module (MPM) with a soft attention mechanism utilizes the produced uncertainty map to refine the coarse predictions of the first stage and predict the final fine segmentation maps (see section 3 of the paper for details about each component).
Re-Labeling ImageNet: From Single to Multi-Labels, From Global to Localized (paper)
One of the flaws of ImageNet is the presence of a significant level of label noise, where many instances contain multiple classes while having a single-label ground-truth. This mismatch between the single label annotations of ImageNet and the multi-label nature of its images becomes even more problematic with random-crop training, where the input may contain an entirely different class than the ground-truth. To aviate this problem, the paper proposes to generate the multi-labels using a strong image classifier trained on an extra source of data, in addition to leveraging pixel-wise multi-label predictions before the final pooling layer as a complementary location-specific supervision signal.
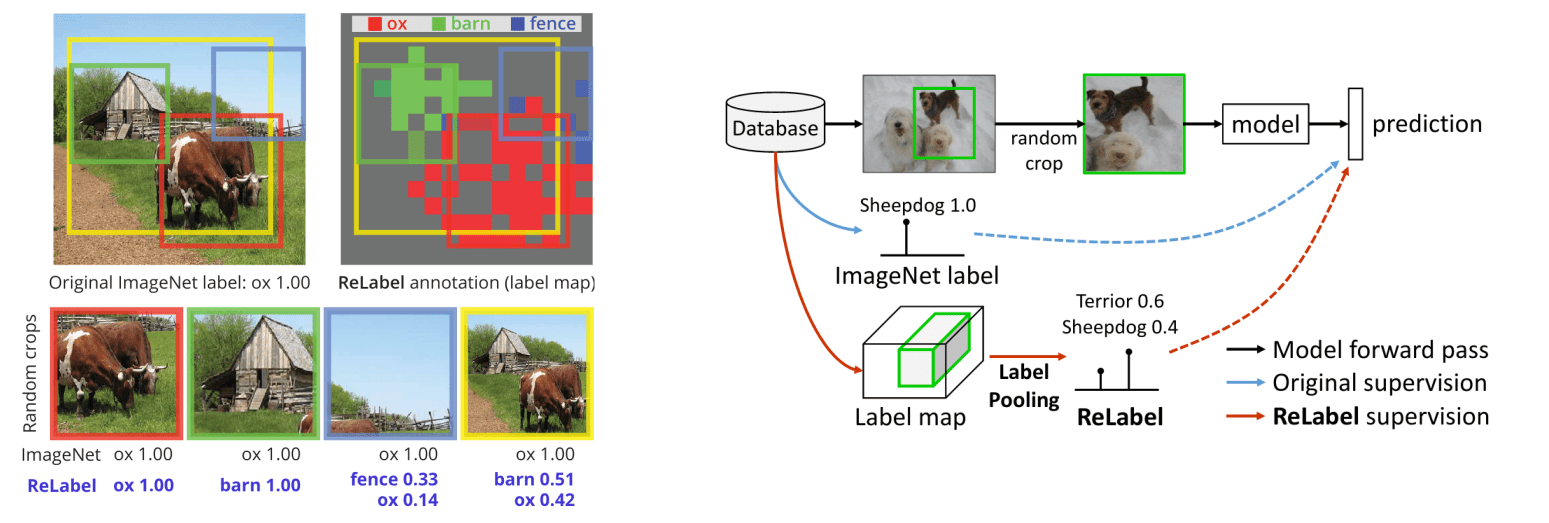
Re-labeling ImageNet consists of using a machine annotator, which is a classifier trained on a super-ImageNet scale datasets (like JFT-300M and InstagramNet-1B) and fine-tunned on ImageNet. While being trained on single-label classification, such classifiers are still capable of multi-label predictions for images with multiple categories, making them suitable for relabeling ImageNet. In addition to generating the multi-label classes, Re-labeling also leverages the location-specific labels, which are the spatial features before the global pooling layer weighted by the weights of the last fully-connected layers. The model is then trained on both the original ImageNet labels and the generated location-specific labels. For the second part, the paper proposes LabelPooling which conducts a regional pooling (RoI Align) operation on the label map corresponding to the coordinates of the random crop (see figure above, right), which are passed to the machine annotator (pretrained then finetuned classifier) to generate the multi-class labels used for the multi-label loss.
Other papers to check out
- You Only Look One-Level Feature.
- Benchmarking Representation Learning for Natural World Image Collections.
- Line Segment Detection Using Transformers Without Edges.
- MoViNets: Mobile Video Networks for Efficient Video Recognition.
- Multimodal Motion Prediction With Stacked Transformers.
- SiamMOT: Siamese Multi-Object Tracking.
Model Architectures & Learning Methods
Pre-Trained Image Processing Transformer (paper)
This paper presents Image Processing Transformer (IPT), a transformer model for low-level computer vision tasks (mainly denoising, super-resolution and deraining). IPT has 4 main blocks. First, multiple heads for extracting features from the inputs, which are the corrupted images such as images with noise and low-resolution images. Each head is a small convolutional net (3 layers) that outputs \(C\) dimensional feature maps of the same spatial dimensions as the input. The standard encoder-decoder transformer blocks for feature refinement and information recovery, with the introduction of task embedding as input seeds into the decoder. Finally, multiple tails that map the transformer’s output features back into the image space.
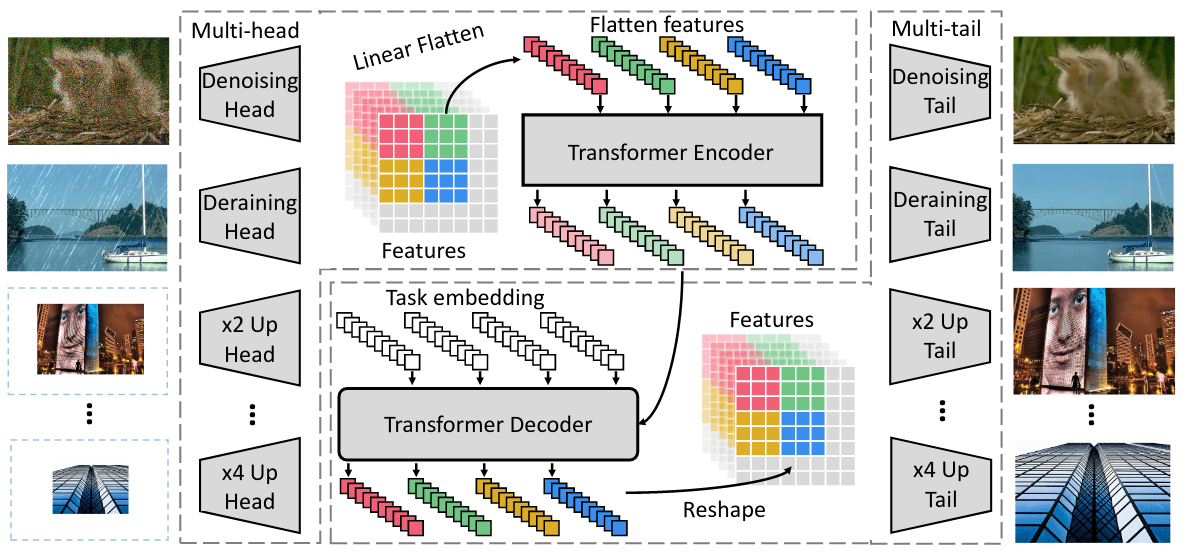
For Pre-training, IPT is trained on corrupted ImageNet inputs. For a given image, first, a corruption function is applied (such as bicubic degradation to generate low-resolution images for super-resolution, or adding Gaussian noise for denoising), the model is then train with an L1 loss between the reconstructed image from the output of IPT and the clean image. Additionally, in order to make IPT applicable to other low-level tasks outside of the introduced corruptions, they also train with a contrastive loss where the model is trained to maximize the similarity between the features of the patches coming from the same input image. After pre-training, the model can then be fine-tuned on the low level task of choice.
RepVGG: Making VGG-Style ConvNets Great Again (paper)
The popular CNN architectures, while delivering good results, still have some drawbacks: 1) The complicated multi-branch designs, such as residual connections in ResNet and branch-concatenation in Inception, making the models more difficult to implement/customize, and slowing down the inference and reduce the memory utilization. 2) Some components such as depthwise convs in MobileNets and channel shuffle in ShuffleNets increase the memory access cost and lack support in various devices. This paper takes a step back in time, and proposes RepVGG, a network with VGG-like design, where at inference-time, the network is composed of nothing but a stack of 3x3 convolutions and ReLUs.
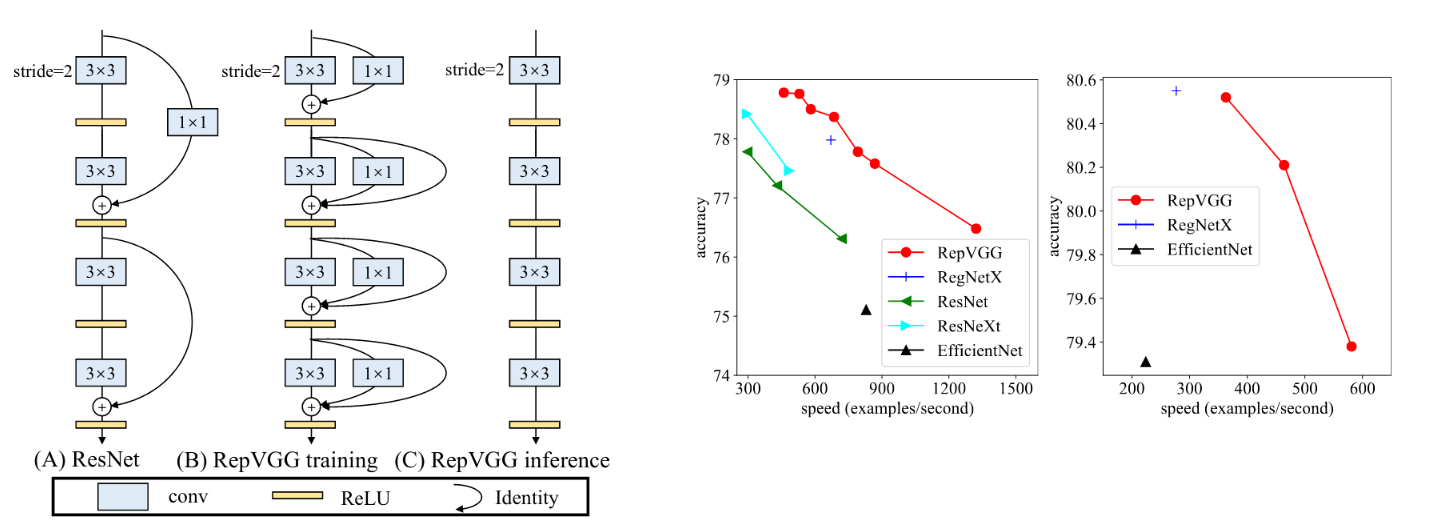
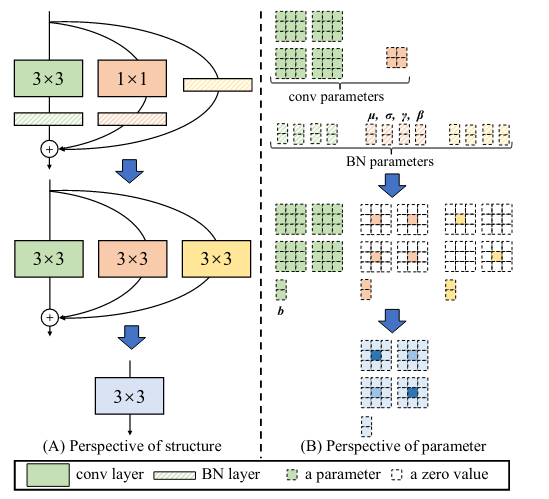
While plain CNNs have many strengths, they possess one fatal weakness: poor performance :). So in the design of RepVGG, there needs to be a multi-branch architecture introduced in training time, and at inference time, RepVGG can then fall back in the plain one branch architecture for efficiency. In order to do this, the design of RepVGG is based on what the paper calls Structural Re-param, which describes how to convert a trained multi-branch block into a single 3x3 conv layer for inference. For a single block with three branches, a 3x3 conv, a 1x1 conv and identity (can be viewed as 1x1 conv with an identity kernel), each one followed by a batch norm, where the output of the block is the sum of the outputs of the three branches. At inference time, RepVGG first converts each conv & the following batch norm of each branch into a single conv with a bias vector. Then, the remaining 3 convs are combined into a single 3x3 conv layer by adding up the biases and adding up the kernels (where the center of 3x3 conv gets the single value in the 1x1 kernel).
Bottleneck Transformers for Visual Recognition (paper)
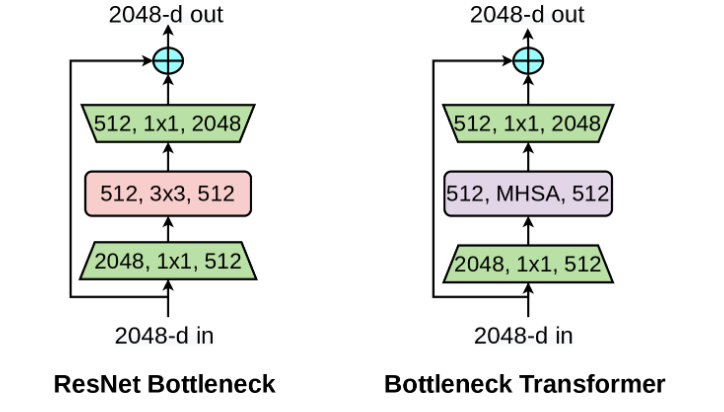
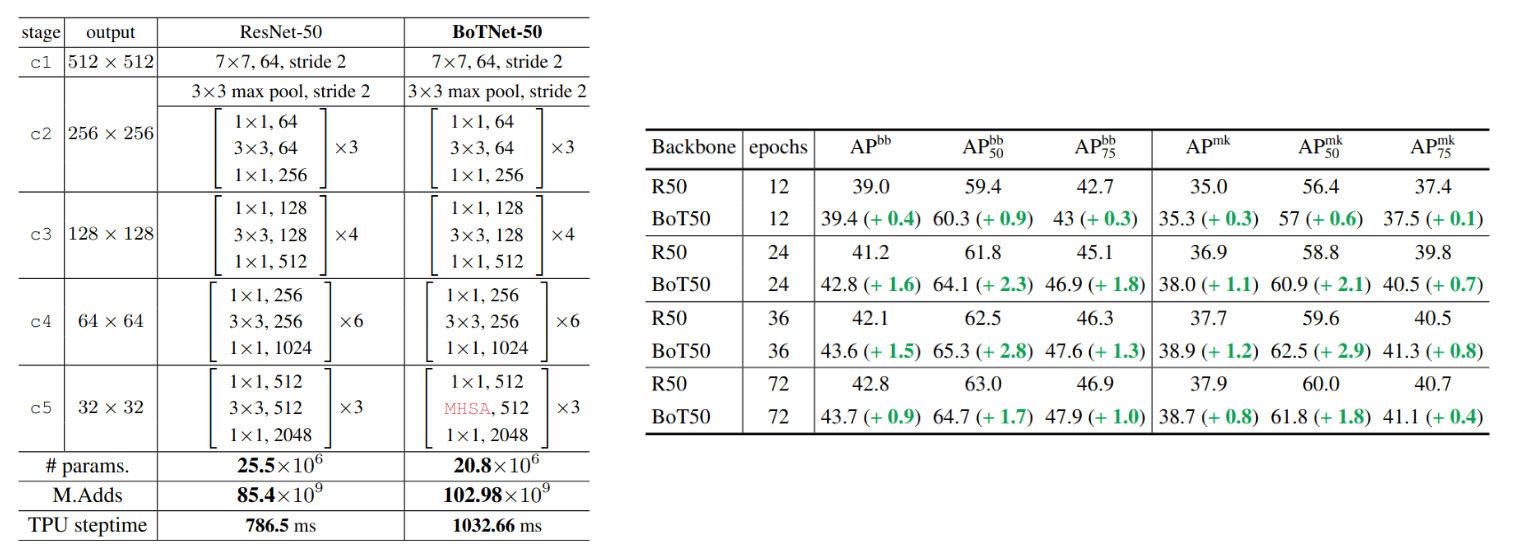
BoTNet, or Bottleneck Transformer, consists of a simple adjustment of the ResNet architecture to incorporate self-attention. This is done by just replacing the spatial convolutions with global self-attention in the final three bottleneck blocks of a ResNet and no other changes. With such an adjudgment, the resulting BoTNet improves upon the ResNet baselines significantly on instance segmentation and object detection while also reducing the parameters, with minimal overhead in latency.
Scaling Local Self-Attention for Parameter Efficient Visual Backbones (paper)
While self-attention models have recently been shown to provide notable improvements on accuracy-parameter trade-offs compared to baseline convolutional models such as ResNet-50, they are still not on par with the high-performing convolutional models such as EfficientNet (V2). In order to close this gap, this paper proposes a new self-attention model family called HaloNets, which is based on a more efficient implementation of self-attention, that improves the speed, memory usage, and accuracy of these models.
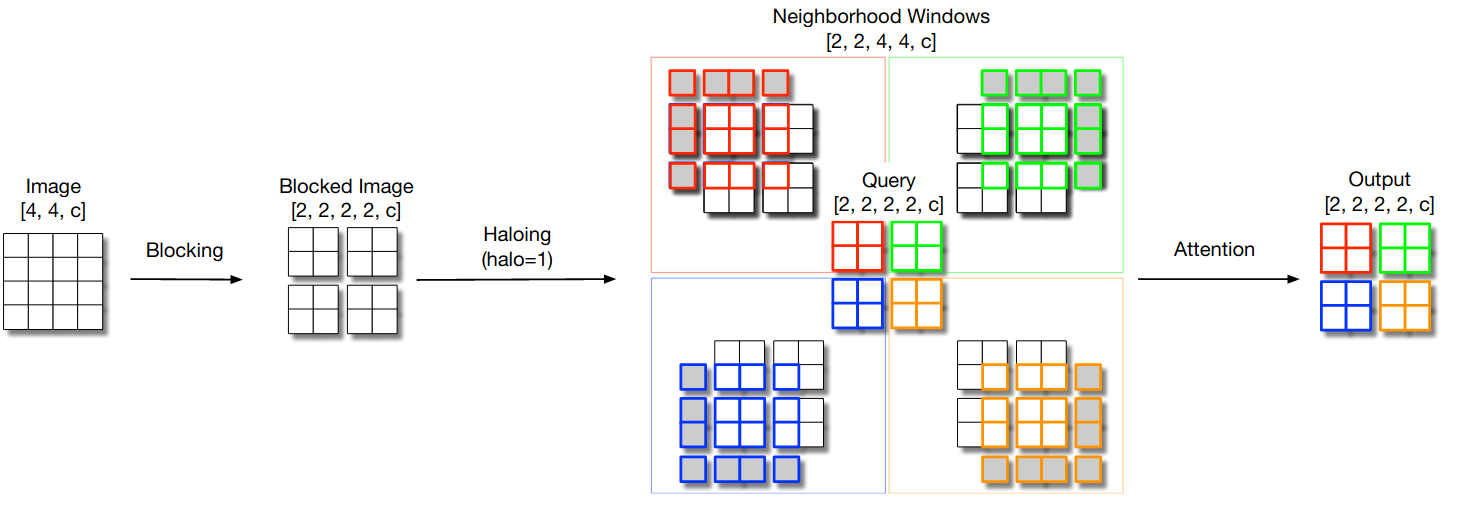
Global self-attention, in which all locations attend to each other, is too expensive for most image scales due to the quadratic computation cost with respect to \(k\) (the kernel size). Thus, self-attention based models like SASA use a local form of self-attention that aggregates the information around each pixel similar to convolutions. However, to do this, we need to extract local 2D grids around each pixel, and such an operation can be quite expensive both computationally and memory wise, since for each pixel, we need to fetch \(k^2\) pixels, and this operation contains a lot of duplicates since two neighboring pixel share most of their neighbors (\(k \times (k-1)\) out of \(k^2\)). To solve this, HaloNets use blocked local self-attention (see figure above), where the local neighborhood for a block of pixels is extracted once together, instead of extracting separate neighborhoods per pixel. This operation consist of first dividing the input tensor into non-overlapping blocks, where each block behaves as a group of query pixels, then a shared neighborhood is constructed around each block, which is used to compute the keys and values and finally the outputs. This way, we only compute one neighborhood per block instead of one neighborhood per pixel (see section 2.2 for more details). After defining such an operation, HaloNets is designed based on a similar architecture to ResNets with blocked local self-attention instead of convolutions.
Involution: Inverting the Inherence of Convolution for Visual Recognition (paper)
Convolution kernels have two main properties, spatial-agnostic, where the same kernel is applied to all of the spatial location of the input volume, and channel-specific, where many kernels is applied over the same input, resulting in an output with multiple channels in order to collect diverse information. These two properties result in an enhanced efficiency and makes the convolution operation translation equivalence. However, with such a design comes some limitations, such as a constrained receptive field where a single conv operation can’t capture long range spatial interactions and a possible inter-channel redundancy inside the convolution filters.
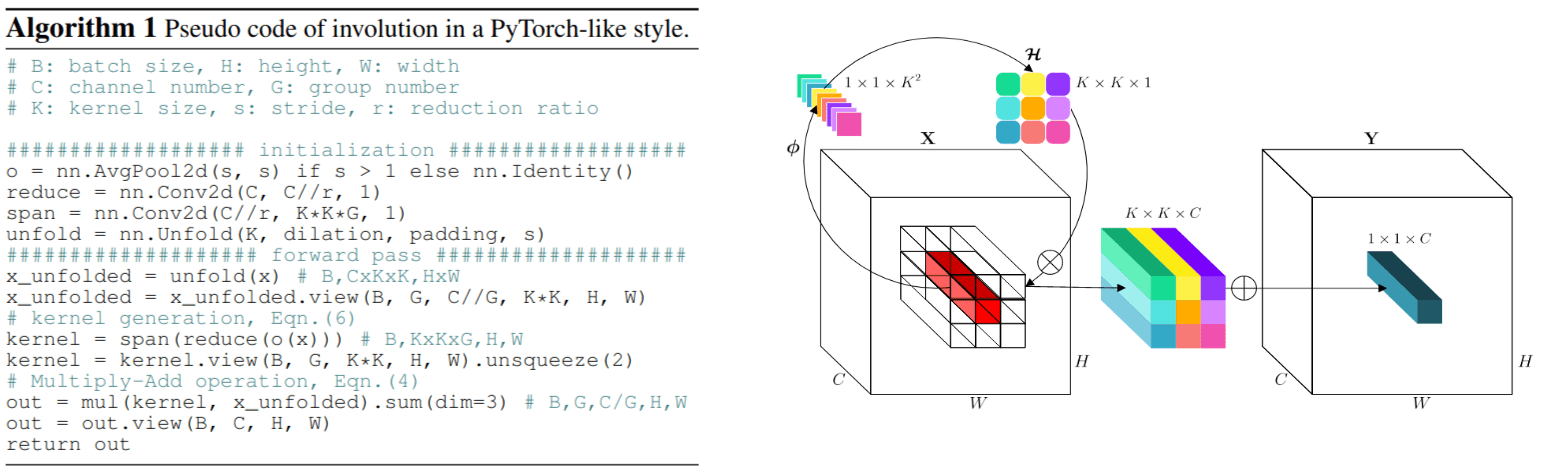
This paper takes a contrarian approach, and proposes an operation called involution that switches the two properties of convolutions, resulting in a spatial-specific and channel-agnostic operation. To have a spatial-specific operation, the involution kernel belonging to a specific spatial location is to be generated solely conditioned on the incoming feature vector at the corresponding location itself. This is implemented in two steps, first a 1x1 conv, where the output channels correspond to the size of the kernel (\(C = k^2\)) is first applied, generating spatial location specific kernel weights (each spatial location will have its own specific conv kernel). The output is then reshaped from one vector per spatial location into a spatial kernel, and then applied over the input volume followed by an aggregation operation (average pooling) over \(k \times k\) volume per spatial location. As for channel-agnostic, it can be obtained by simply sharing the convolution over all channels. This operation is then used to design RedNet, a ResNet style model with involutions.
On Feature Normalization and Data Augmentation (paper)
The usage of normalization techniques such as bach norm in recognition models have become a standard practice, where the moments (ie, mean and standard deviation) of latent features are often removed when training image recognition models, which helps increase their stability and reduce the training time. However, such moments can play a much more central role in some vision tasks like image generation, where they capture style and shape information of an image and can be instrumental in the generation process. In this context, this paper proposes Moment Exchange or MoEx, an implicit data augmentation method that encourages the recognition model to utilize the moment information for better performances and better robustness.
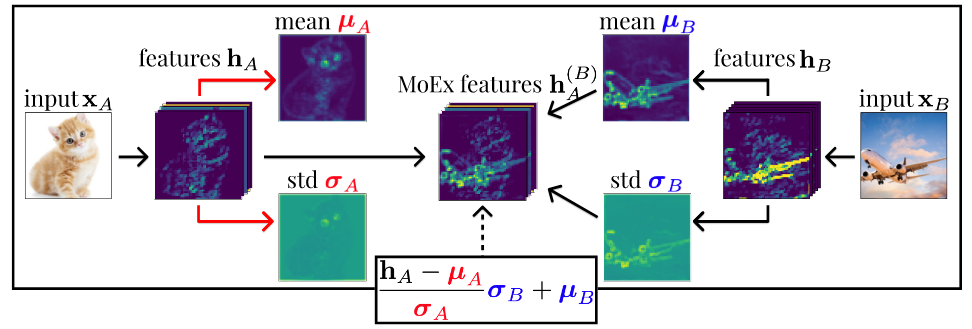
MoEx is an operation applied in the feature space in order to systematically regulate how much attention a network pays to the signal in the feature moments. As illustrated above, given an input, the mean and variance across channels are first extracted after the first layer. Then, instead of removing them, they are swapped with the moments of an other image that are extracted in the same manner. This results in a set of features that contain information about both images, and then the model is then trained to predict an interpolation of the labels of the two inputs. This way, the model is pushed to focus on two different signals for classification, the normalized feature of the first image and the moments of the second.
- MIST: Multiple Instance Spatial Transformer
- Simple Copy-Paste Is a Strong Data Augmentation Method for Instance Segmentation
- Decoupled Dynamic Filter Networks
- Skip-Convolutions for Efficient Video Processing
- Metadata Normalization
3D Computer Vision
MP3: A Unified Model to Map, Perceive, Predict and Plan (paper)
Most modern self-driving stacks require up-to-date high-definition maps that contain rich semantic information necessary for driving, such as the topology and location of the lanes, crosswalks, traffic lights, intersections as well as the traffic rules for each lane. While such maps greatly facilitate the perception and motion forecasting tasks, as the online inference process has to mainly focus on dynamic objects (eg, vehicles, pedestrians, cyclists), scaling them is hard given their complexity and cost, and given that even very small errors in the mapping might result in fatal mistakes. This motivates the development of mapless technology, which can serve as a fail-safe alternative in the case of localization failures or outdated maps, and potentially unlock self-driving at scale at a much lower cost.
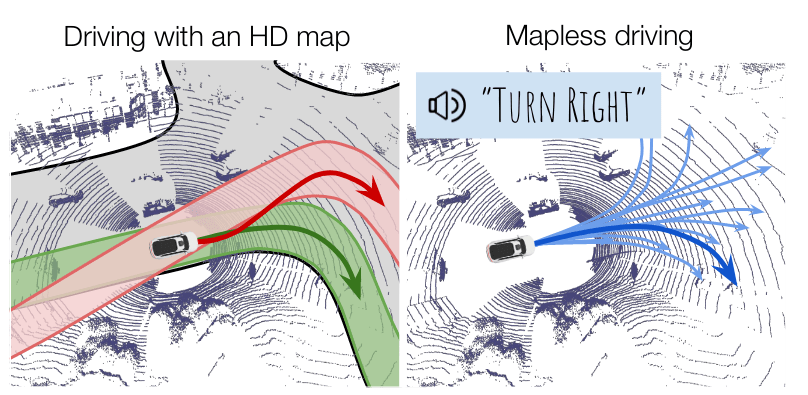
However, with a mapless approach comes a number of challenges: (1) The sole source of training signal is the controls of an expert driver (such steering and acceleration), without providing intermediate interpretable representations that can help explain the self-driving vehicle decisions. (2) Without any mechanism to inject structure and prior knowledge, such an approach can be very brittle to distributional shift such missing a lane. To address these issues, the paper presents MP3, an end-to-end approach to mapless driving that is interpretable, does not incur any information loss, and reasons about uncertainty in the intermediate representations.
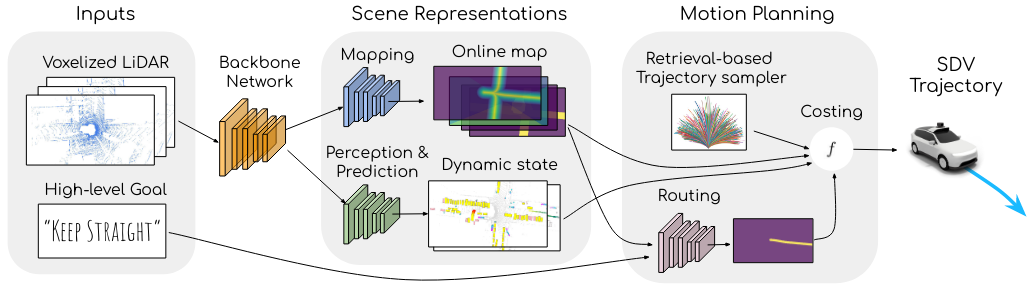
The MP3 model takes as input a high-level goal, a history of LiDAR point clouds to extract rich geometric and semantic features from the scene over time (see this for more details), and odometry data to compensate for the vehicle’s motion. The inputs are then processed using a backbone network and fed into a set of probabilistic spatial layers to model the static and dynamic parts of the environment. The static environment is represented by a planning-centric online map which captures information about which areas are drivable and which ones are reachable given the traffic rules. The dynamic actors are captured in a novel occupancy flow that provides occupancy and velocity estimates over time. The motion planning module then leverages these representations to retrieve dynamically feasible trajectories, predicts a spatial mask over the map to estimate the route given an abstract goal, and leverages the online map and occupancy flow directly as cost functions for explainable, safe plans.
Multi-Modal Fusion Transformer for End-to-End Autonomous Driving (paper)
In a standard driving situation such as the one depicted in the left image bellow, the vehicle must capture the global context of the scene involving the interaction between the traffic light (yellow) and the vehicles (red) for a safe navigation. To do this, the different modalities (ie, the LiDAR point cloud and the camera view) must be fused together in order to obtain such a global view. This raises the following questions: how to fuse such multi-modal representations? to what extent each modality should be processed independently before fusion? and how can such fusion be conduced?. The paper proposes a Modal Fusion Transformer (TransFuser), a transformer-based model designed to integrate both LiDAT and camera views with global attention, thus capturing the necessary 3D context for safe navigation.
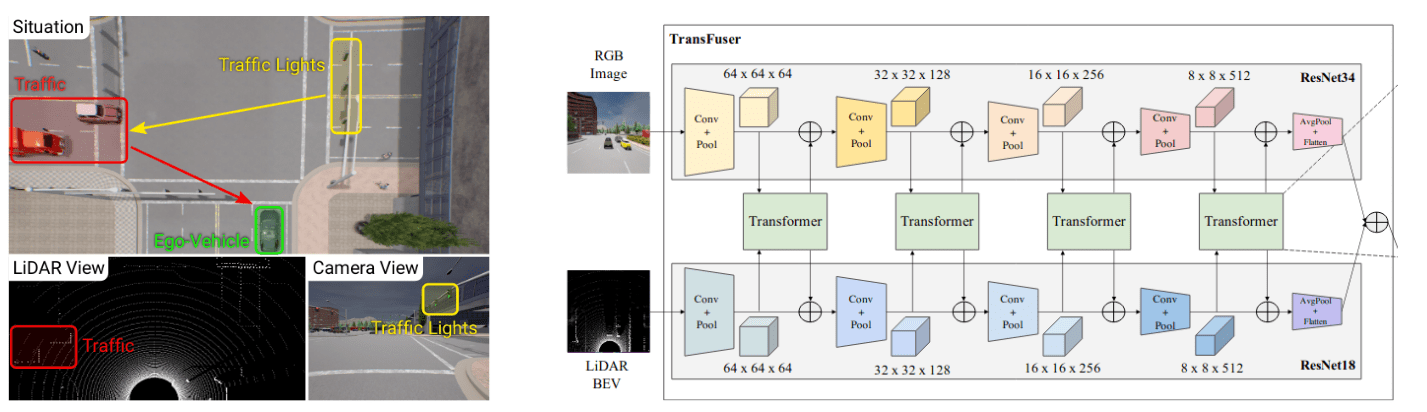
The paper considers the task of point-to-point navigation in an urban setting, where the goal is to complete a given route while safely reacting to other dynamic agents and following traffic rules. The TransFuser is trained using an L1 loss between the predicted trajectories and the correct trajectories using a dataset consisting of high-dimensional observations of the environment, and the corresponding expert trajectory. TransFuser takes as input RGB images and LiDAR BEV representations and uses several transformer modules to fuse the intermediate feature maps between both modalities. The fusion is applied at multiple resolutions and throughout the feature extractor resulting in a 512-dimensional feature vector output from both the image and LiDAR BEV stream, which is the desired compact representation of the environment that encodes the global context of the 3D scene. This compact representation can then be used as input to an auto-regressive (a GRU) prediction network that outputs the trajectories in the form of waypoints in vehicle’s coordinate frame.
Neural Lumigraph Rendering (paper)
The recent neural rendering techniques are capable of generating photorealistic image quality for novel view synthesis and 3D shape estimation from 2D images. But they are either slow to train and/or require a considerable rendering time time for high image resolutions. NeRF for instance does not offer real-time rendering due to the use of neural scene representation and volume rendering. To overcome this, the paper proposes the use SDF-based sinusoidal representation network (SIREN) to implicitly model the surface of objects (ie, implicitly defining an object or a scene using a neural network and training directly with 3D data), which can be extracted using the marching cubes algorithm and exported into traditional mesh-based representations for real-time rendering.
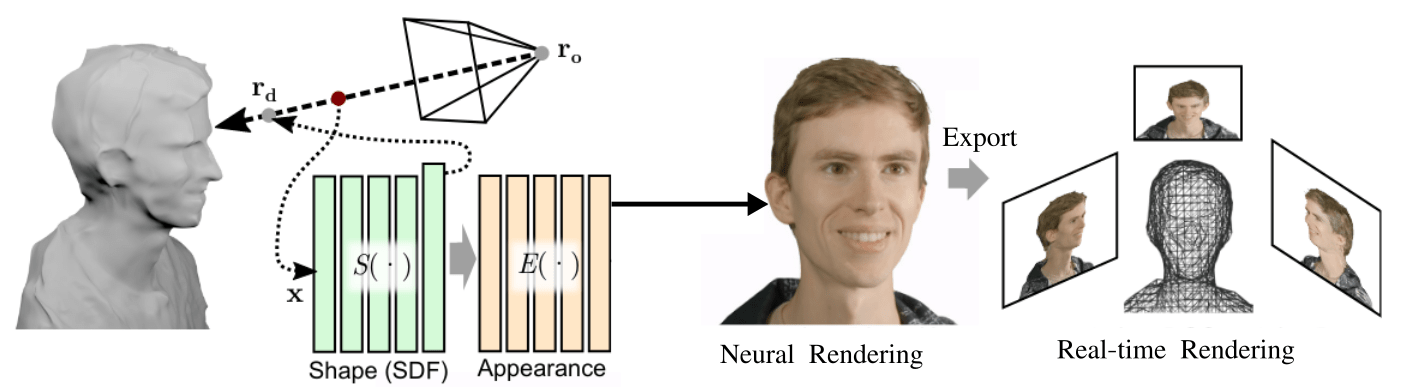
However, given the high capacity of SIRENs, they are prone to overfitting, making them incapable of rendering new views that are interpolations of views encountered during training. To solve this, the authors propose a novel smoothness loss function that maintains SIREN’s high-capacity encoding in the image domain while constraining it in the angular domain to prevent overfitting on these views. The SIREN based network can then be trained using a sparse set of multi-view 2D images while providing a high-quality 3D surface that can be directly exported for real-time rendering algorithms at test time.
NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis (paper)
NeRV extends NeRF to arbitrary lighting conditions, taking as input a set of images of a scene illuminated by unconstrained lighting, and producing a 3D representation that can be rendered from novel viewpoints under novel and unobserved lighting conditions.
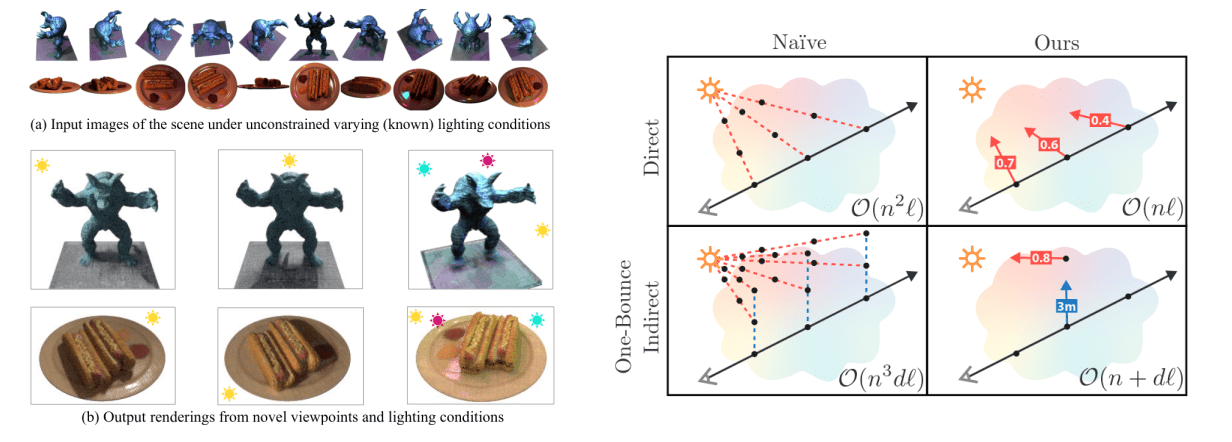
Given that NeRF models just the amount of outgoing light from a location, the fact that this out going light is itself the result of interactions between incoming light and the material properties of an underlying surface is ignored, so rendering viewpoints under novel lighting conditions is not possible. A naive way (figure above, right) to solve this is to query NeRF’s MLP for the volume density at samples along the camera ray to determine the amount of light reflected at each location that reaches the camera. Then for each location, query the MLP for the volume density at points between the location and every light source. This procedure is clearly too computationally infeasible. The paper solve this by proposing NeRV, a method to train a NeRF-like model that can simulate realistic environment lighting and global illumination by using an additional MLP as a lookup table into a visibility field during rendering. As a result, the training consists of jointly optimizing the visibility MLP (or reflectance MLP) for estimating the light surface visibility at a given 3D position along, alongside the NeRF’s MLP (also called the shape MLP) for volumetric representation. At test time, the rendering is then conducted along the ray by querying the shape and reflectance MLPs for the volume densities, surface normals, and BRDF parameters at each point.
Neural Body: Implicit Neural Representations With Structured Latent Codes for Novel View Synthesis of Dynamic Humans (paper)

Given a very sparse set of camera views (say 3 or 4 views as depicted above), learning implicit neural representations of 3D scenes becomes infeasible. To solve this, the paper proposes Neural Body, a method that leverages observations over video frames order to learn a new human body representation that is consistent over the different frames, and shares the same set of latent codes anchored to a deformable mesh, so that the observations across frames can be naturally integrated.
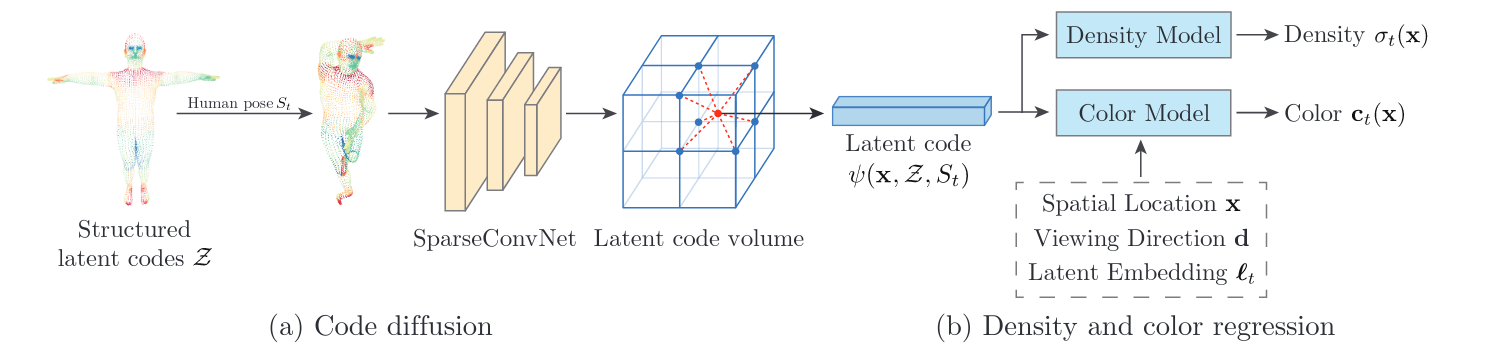
First, a set of latent codes are defined and anchored to the vertices of the SMLP deformable human model, so that the spatial location of each vertex varies with the human pose. Then, the 3D representation at a given frame is estimated from sparse camera views, and then applied to the code location based on the obtained 3D human pose. Finally, the network is trained to regress the density and color for any 3D point based on these latent codes. Both the latent codes and the network are jointly learned from images of all video frames during the reconstruction process.
pixelNeRF: Neural Radiance Fields From One or Few Images (paper)
The NeRF framework consists of optimizing the representation of every scene independently, requiring many views per scene and a significant compute time. pixelNeRF adapts NeRF in order to be trained across multiple scenes jointly to learn a scene prior, enabling it to perform novel view synthesis in a feed-forward manner from a sparse set of views (as few as one). This is done by using spatial features of a given image produced by a CNN, which are aligned to each pixel as an input, and then passes through NeRF model for training. This simple image conditioning allows the model to be trained on a set of multi-view images, where it can learn scene priors to perform view synthesis.
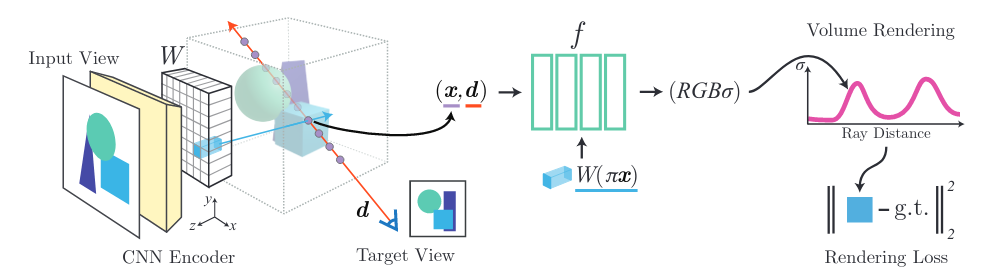
pixelNeRF consists of two components: a fully-convolutional image encoder, which encodes the input image into a pixel-aligned feature grid, and a NeRF network which outputs color and density given a spatial location and its corresponding encoded feature. When multiple input views are available, each view is encoded into the feature grid, the multiple features are processed in parallel and then aggregated into the final color and opacity.
Other papers to check out
- Dynamic Neural Radiance Fields for Monocular 4D Facial Avatar Reconstruction
- NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
- D-NeRF: Neural Radiance Fields for Dynamic Scenes
- Learning to recover 3D Scene Shape from a single image
- NeuralRecon: Real-Time Coherent 3D Reconstruction From Monocular Video
- Point2Skeleton: Learning Skeletal Representations from Point Clouds
- Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos
- NeX: Real-Time View Synthesis With Neural Basis Expansion
- Holistic 3D Scene Understanding From a Single Image With Implicit Representation
- Scan2Cap: Context-aware Dense Captioning in RGB-D Scans
- Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction
- Exploring Data-Efficient 3D Scene Understanding with Contrastive Scene Contexts
- Learning Delaunay Surface Elements for Mesh Reconstruction
- A Deep Emulator for Secondary Motion of 3D Characters
- NeuTex: Neural Texture Mapping for Volumetric Neural Rendering
- DeRF: Decomposed Radiance Fields
- IBRNet: Learning Multi-View Image-Based Rendering
- Learned Initializations for Optimizing Coordinate-Based Neural Representations
- AutoInt: Automatic Integration for Fast Neural Volume Rendering
- Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos
- Back to the Feature: Learning Robust Camera Localization From Pixels To Pose
- Wide-Baseline Relative Camera Pose Estimation With Directional Learning
- Pulsar: Efficient Sphere-Based Neural Rendering
- Neural Geometric Level of Detail: Real-Time Rendering With Implicit 3D Shapes
- Deep Multi-Task Learning for Joint Localization, Perception, and Prediction
- KeypointDeformer: Unsupervised 3D Keypoint Discovery for Shape Control
- Shelf-Supervised Mesh Prediction in the Wild
- LoFTR: Detector-Free Local Feature Matching With Transformers
- Shape and Material Capture at Home
- SPSG: Self-Supervised Photometric Scene Generation From RGB-D Scans
- Fusing the Old with the New: Learning Relative Camera Pose with Geometry-Guided Uncertainty
- Cuboids Revisited: Learning Robust 3D Shape Fitting to Single RGB Images
- MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments From a Single Moving Camera
- DECOR-GAN: 3D Shape Detailization by Conditional Refinement
Image and Video Synthesis
GIRAFFE: Representing Scenes As Compositional Generative Neural Feature Fields (paper)
While GaNs are capable of generating photorealistic and diverse high resolutions images, having a fine-grained control over the factors of variation in the data and the compositionality of the generated scenes is sill limited, operating only in 2D and ignoring the three-dimensional nature of the underlying scenes.
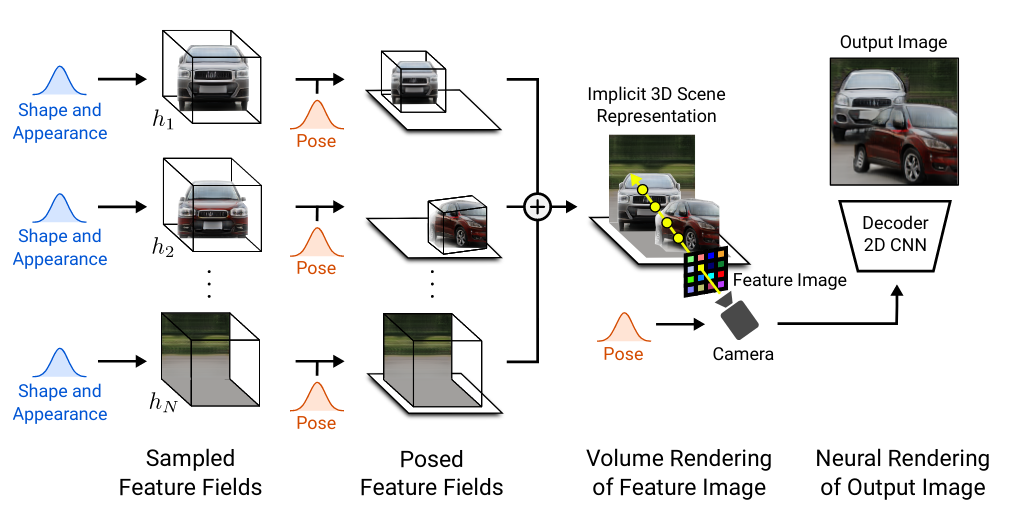
GIRAFFE proposes to represent scenes as compositional generative neural feature fields. During training, instead of having a single latent code as in the standard GaN setting, GIRAFFE randomly generated a set of Shape and Appearance codes for each object (& background) in the scene, which are used to generated Feature Fields. Then a second set of latent codes are generated, this time representing the pose transformation, which are applied to the generated Feature standard to obtain the Posed Feature Fields. Finally, the final Posed Feature Fields are aggregated into a single scene representation, and given a camera pose, are used as input to the neural rendering network to generate a 2D image. The generated and real 2D images are then passed to the discriminator to compute the adversarial loss. The whole model is trained end-to-end, and at test time, the composition of the generated images can be controlled using the Shape & Appearance and Pose latent codes.
GeoSim: Realistic Video Simulation via Geometry-Aware Composition for Self-Driving (paper)

The ability to simulate/enhance various real world scenarios is an important yet challenging open problem, especially for safety-critical domains such as self-driving where producing visually appealing and realistic results requires a physics-based rendering, which is very costly. As a, alternative, GeoSim exploits the recent advances in image synthesis by combining data driven approaches (such as generative modeling) and computer graphics to insert dynamic objects into existing videos, while maintaining high visual quality through physically grounded simulation (see the example above).
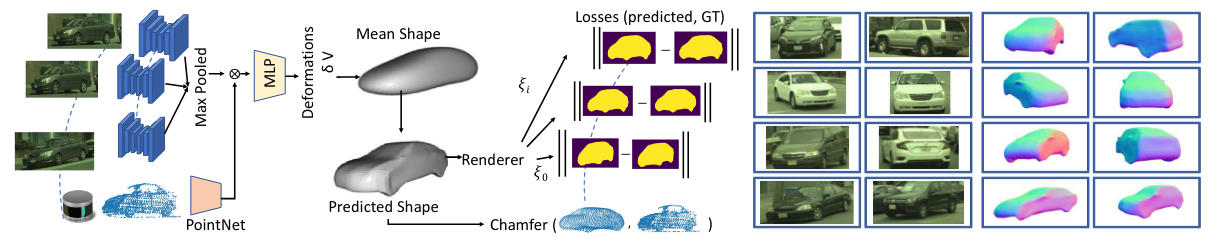
The first step of GeoSim is to create a large 3D assets (vehicles of different types and shapes) with accurate pose, shape and texture. Instead of using artists to create these assets, GeoSim leverages publicly available datasets to construct 3D assets of the objects. This is done using a learning-based, multi-view, multi-sensor reconstruction approach that leverages the 3D bounding boxes and trained in a self-supervised manner so that there is an agreement between the predicted 3D shape and that of the camera and LiDAR observations. GeoSim then exploits the 3D scene layout from high-definition maps and LiDAR data to add these learned 3D assets in plausible locations and make them behave realistically by considering the full scene. Finally, using this new 3D scene, GeoSim performs image-based rendering to properly handle occlusions, and neural network-based image in-painting to ensure the inserted object seamlessly blends in by filling holes, adjusting color inconsistencies due to lighting changes, and removing sharp boundaries. Check out the paper’s website for some results.
Taming Transformers for High-Resolution Image Synthesis (paper)
The recently introduced vision transformers (such as ViT) demonstrated that they can perform on par with CNNs, and given enough training data, they tend to learn convolutional structures. This raises an obvious question, do we have to relearn such an inductive bias from scratch each time we train a vision model?. This paper proposes to merge both CNNs and transformers into a single framework for image synthesis. Thus leveraging the efficiency of CNNs and their inductive image biases while still retaining the flexibility of transformers.
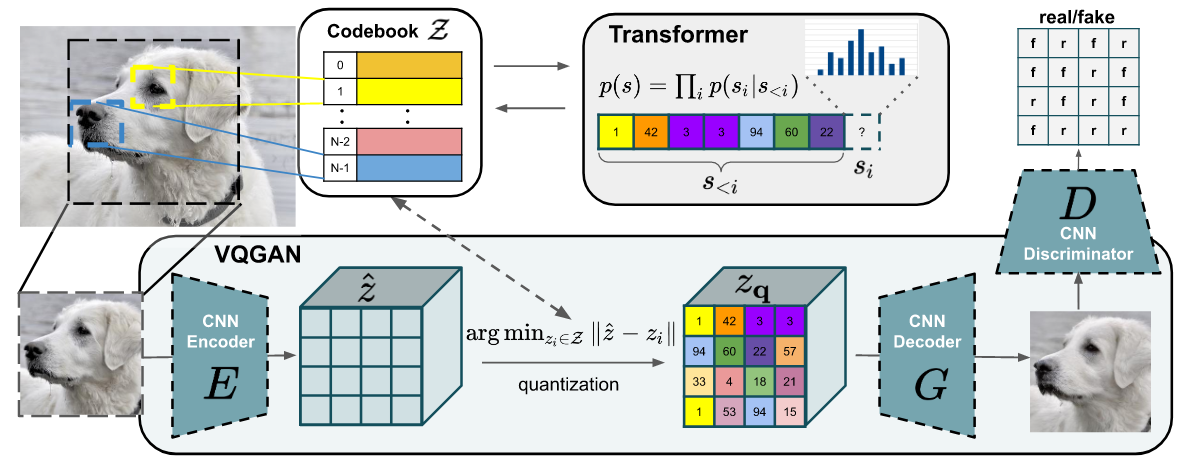
As depicted above, the proposed framework consists of CNN encoder-decoder network trained adversarially for Neural Discrete Representation Learning, and then a transformer that operates over the discrete representations in an autoregressive manner. More specifically, the training consist of two stages. First, the encoder, the decoder and the discriminator, all CNN-based, are trained using a reconstruction loss, a perceptual loss, a commitment loss (ie, used to refine the codebook, see VQVAE for more details), and an adversarial loss. At the end of training, we end-up with a learned codebook where each spatial location in the input image can be represented by an index in the codebook. By using such a formulation, the input image can be viewed as a sequence of codebook indices, and such a sequence can be used to train the auto-regressive transformer in the second step of the training process. Starting from the top left corner, at each time step, the transformer is tasked with predicting the next codebook index, and in order to reduce the computation, the input to the transformer is restricted into a sliding window without a significant loss in performance. Finally, at test time, we can use the trained transformer to generate large sequences without any restrictions (and with any type of conditioning, see section 3.2 of the paper), which correspond to very large images. The predicted indices are then used to fetch the discrete representations from the codebook, which are then passed to the decoder to synthesis an image.
Rethinking and Improving the Robustness of Image Style Transfer(Paper)
The objective of image style transfer is to map the content of a given image into the style of a different one, and in such a task, VGG network has demonstrated a remarkable ability to capture the visual style of an image. However, when such a network is replaced with a more modern, and a better performing network such as ResNet, the stylization performance degrades significantly as shown in the figure bellow.

In this paper, the authors investigate the root cause of this behavior, and find that residual connections, which represent the main architectural difference between VGG and ResNet, produce peaky feature maps of small entropy, which are not suitable for style transfer. To improve the stylization of the ResNet architecture, the authors then propose a simple yet effective solution based on a softmax transformation of the feature activations that enhances their entropy. This method, dubbed Stylization With Activation smoothinG (SWAG), consists of adding a softmax-based smoothing transformation to all of the activations in order to push the model to produce smoother activations, thus reducing large peaks and increasing small values, creating a more uniform distribution.
Learning Continuous Image Representation With Local Implicit Image Function (Paper)
This paper proposes Local Implicit Image Function (LIIF) for representing natural and complex images in a continuous manner. With LIIF, an image is represented as a set of latent codes distributed in spatial dimensions. Given a coordinate, the decoding function takes the coordinate information and queries the local latent codes around it, and then predicts the RGB value at the given coordinate as an output. Since the LIIF representation is continuous, we can query an arbitrary high target resolution up to x30 higher than the resolution encountered during training.
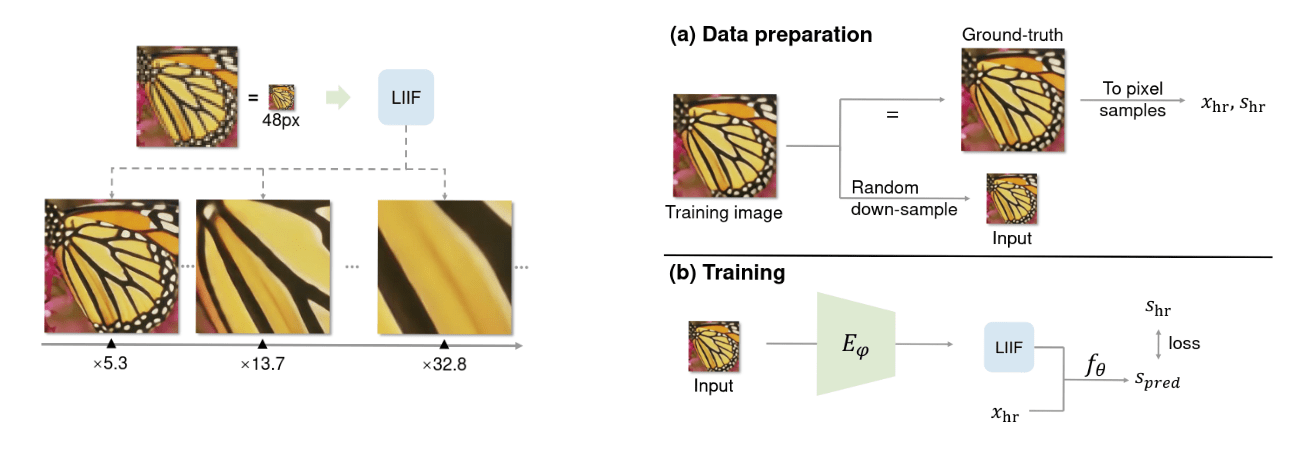
The proposed framework consists of an encoder that produces 2D feature maps given an input image, where the feature maps are evenly distributed in the 2D space of the continuous image domain, and each feature at a given spatial location is called a latent code. Then, the decoder takes as input a 2D coordinate in the image domain in addition to a weighted average of the 4 nearest latent codes of the chosen 2D coordinate and outputs the RGB values. Now, in order to train both the encoder and the decoder jointly using self-supervision, this is done by taking a training image, randomly down-sampling it, the encoder then encodes the down-sampled image, while the decoder is queried to produced the RGB values of the original image, which is used as ground-truth.
Other papers to check out
- Ensembling with Deep Generative Views
- SSN: Soft Shadow Network for Image Compositing
- Spatially-Adaptive Pixelwise Networks for Fast Image Translation
- DriveGAN: Towards a Controllable High-Quality Neural Simulation
- Motion Representations for Articulated Animation
- Playable Video Generation
- Repopulating Street Scenes
- Animating Pictures With Eulerian Motion Fields
- Closed-Form Factorization of Latent Semantics in GANs
- Stylized Neural Painting
- Image Generators With Conditionally-Independent Pixel Synthesis
- Cross-Modal Contrastive Learning for Text-to-Image Generation
- Dual Contradistinctive Generative Autoencoder
- Space-Time Neural Irradiance Fields for Free-Viewpoint Video
- Positional Encoding As Spatial Inductive Bias in GANs
- Regularizing Generative Adversarial Networks Under Limited Data
- Variational Transformer Networks for Layout Generation
- Deep Animation Video Interpolation in the Wild
- Stable View Synthesis
- Navigating the GAN Parameter Space for Semantic Image Editing
- Stochastic Image-to-Video Synthesis Using cINNs
- Exploiting Spatial Dimensions of Latent in GAN for Real-Time Image Editing
- Plan2Scene: Converting Floorplans to 3D Scenes
- SceneGen: Learning to Generate Realistic Traffic Scenes
- OCONet: Image Extrapolation by Object Completion
- Anycost GANs for Interactive Image Synthesis and Editing
- StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation
- Encoding in Style: A StyleGAN Encoder for Image-to-Image Translation
- Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes
- One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing
- Training Generative Adversarial Networks in One Stage
- Generative Hierarchical Features From Synthesizing Images
Scene Analysis & Understanding
Rethinking Semantic Segmentation From a Sequence-to-Sequence Perspective With Transformers (Paper)
The proposed SEgmentation TRansformer (SETR) is based on an alternative formulation of semantic segmentation as a sequence-to-sequence task. This way, instead of using the standard encoder-decoder architecture, such a formulation gives us the possibility to employ a pure transformer without convolution and resolution reduction for pixel-level classification, since it is in line with the way transformers operate over the inputs and how they produce the predictions. In addition to leveraging the capability of a transformer layer to model the global context which important for sematic segmentation in order to obtain coherent masks.
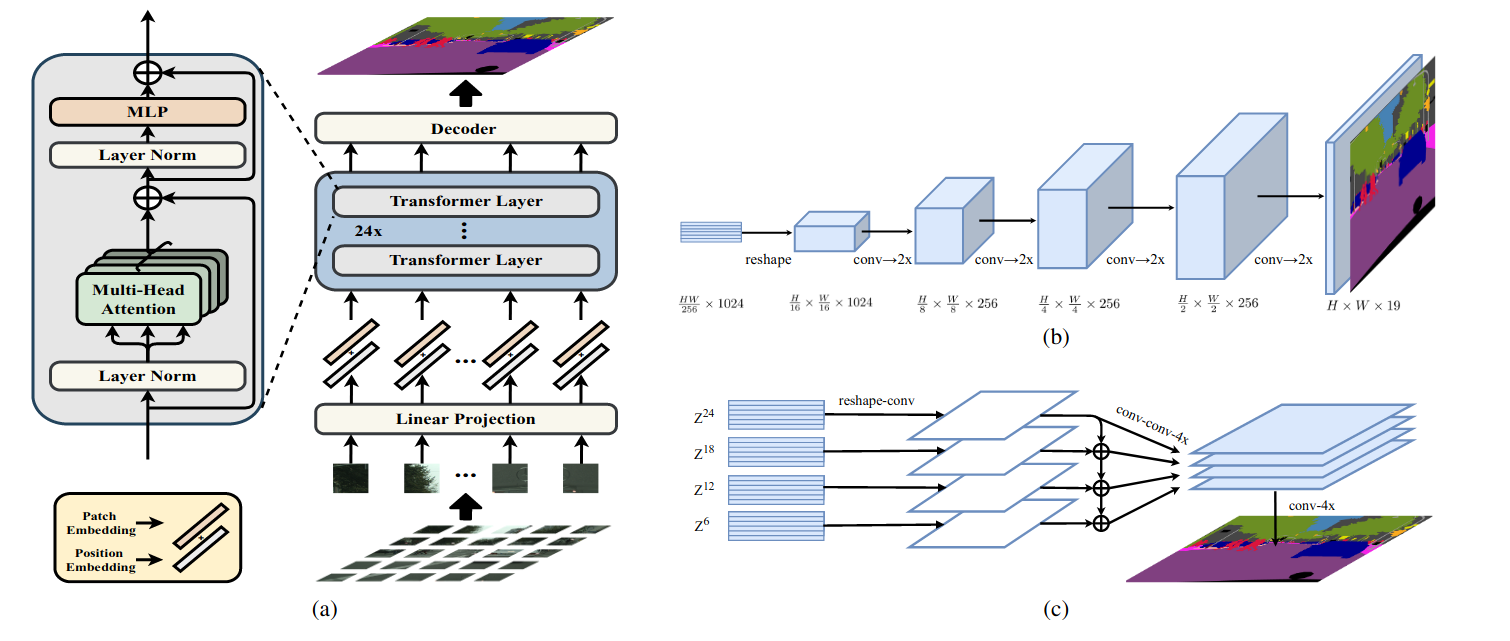
SETR (figure above, a) treats an input image as a sequence of image patches, where each image is first decomposed into a fixed-sized patches. Then, each path is flattened into a vector of pixel values and passed through a linear layer, outputting the patch embedding. These patch embedding are passed as a sequence to the transformer-encoder (ie, 24 transformer layers) with the global self-attention in order to discriminative features tailored for the segmentation task. The produced representations are then reshaped from 2D shape (number of patches x embedding dimensionality) back into the standard 3D features map shape (H x W x embedding dimensionality). The reshaped features are then passed to the decoder to predict the final per pixel classification at the original input size. Here, SETR proposes 3 types of decoders: (1) Naive upsampling: a 2-layer network followed by bilinear upsampling, (2) Progressive UPsampling: alternates between conv layers and a single 2x bilinear upsampling operation (figure above, b). (3) Multi-Level feature Aggregation: apply many levels of conv layers & 4x by bilinear upsampling over the encoder’s output, merge them and apply a final upsampling (figure above, c).
MaX-DeepLab: End-to-End Panoptic Segmentation With Mask Transformers (Paper)
MaX-DeepLab is an end-to-end model for panoptic segmentation without any hand-designed components such as box detection, non-maximum suppression, or thing-stuff merging. MaX-DeepLab directly predicts class-labeled masks with a mask transformer, and is trained with a panoptic quality inspired loss via bipartite matching.
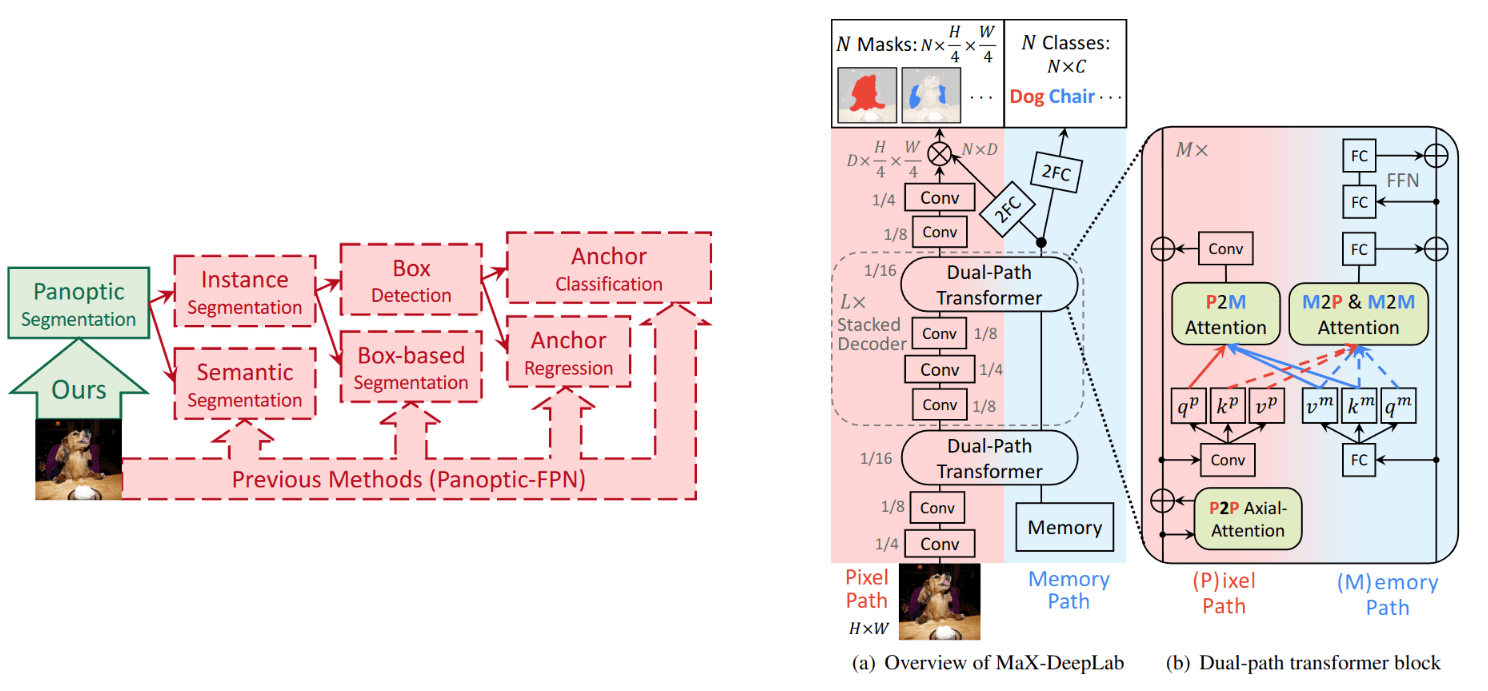
Building upon the recent transformer-based end-to-end object detectors such as DERT or Deformable DETR, MaX-DeepLab directly outputs non-overlapping masks and their corresponding semantic labels with a mask transformer. The model is then trained with a novel panoptic quality style loss (see section 3.2). This loss measures the similarity between ground-truth and predicted class-labeled masks as the multiplication of their mask similarity and their class similarity, and since the MaX-DeepLab outputs a larger number of masks than the ground-truths, a one-to-one matching is applied (as in DERT) before computing the loss.
As for the architecture, MaX-DeepLab integrates transformer blocks (called dual-path transformer) along a given CNN backbone in a dual-path fashion, with bidirectional communication blocks between the two paths. Each 2D pixel-based CNN is augmented with 1D global memory (of the same size as the number of predictions) with different types of attention. Specifically, a dual-path transformer takes as input the 2D CNN features and 1D memory, and applies 4 types of attention: 1) pixel-to-pixel over the CNN features, and since the attention over spatial dimensions is expensive, they use axial-attention. 1) memory-to-memory updating the memory features with global context, and then the cross-attention, 3) pixel-to-memory and 4) memory-to-pixel attention, where each time the query of one is applied to the keys and values of the other to update either the pixel or memory features conditioned on the other.
Binary TTC: A Temporal Geofence for Autonomous Navigation (Paper)
Path planning, whether for robotics or automotive applications, requires accurate perception, and one of main task used to acquire such an accurate perception is depth information. To infer depth, the most popular strategy is to use LiDAR which is capable of estimating depth, but only at sparse locations and can be quite expensive. Another alternative is to only use monocular cameras (this is the Tesla approach) to construct the optical flow between consecutive frames, which carries information on the scene’s depth, while greatly reducing the acquisition and maintenance costs. But this approach also has its drawback since it can only be estimated reliably in constrained and simple scenes. In this context, and since the objective behind the perception is to inform decisions, Binary TTC proposes to replace learning to infer depth with a new and simpler task that can be directly used to inform planning decisions.

The proposed Binary TTC task is based on the concept of time-to-contact (TTC), which is the time for an object to collide with the camera plane under the current velocity conditions, and consists of predicting a binary classification map, where the objects that will collide with the camera plane within a given time are assigned labels of 1. More specifically, a binary classification network is trained to detect the objects that will collide with the camera plane for a given time interval. To train the network, the labels are generated using two images of a given dynamic scene, then, the sizes of each moving object in the two images are compared (after a scaling is applied to take into account the chosen time of collision). If the size becomes larger from the first to the second image, this means that the object is getting closer to the camera plane and can be labeled as 1.
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging (Paper)

The paper starts with a analysis of the behavior of standard monocular depth estimation models (they use MiDaS) when fed images at different resolutions. With small resolutions, the estimations lack many high-frequency details while generating a consistent overall structure of the scene. As the input resolution gets higher, more details are generated in the result but with inconsistencies in the scene structure characterized by gradual shifts in depth between image regions.
Based on the above observation, the paper proposes to merge depth estimates at different resolution with an image-to-image translation network that merges these estimates into a final prediction. In order to determine the input resolutions which to be merged later, the authors propose to base this selection on the number of pixels that do not have any contextual cues nearby. These regions with the lowest contextual cue density will dictate the maximum resolution that can be used for an image. Additionally, in order to also benefit from higher-resolution estimations to generate more high-frequency details, a patch based selection method is used to find regions with higher contextual cue density that requires more high-frequency details, which are then merged together for the final results.
Check out the authors video for a brief but great explanation of the work.
Polygonal Building Extraction by Frame Field Learning (Paper)
For the task of building segmentation where the objective is to output a polygon for each building in a given aerial photo, the existing approach are either based on vector representations, directly predicting vector polygons, or two step approach that first produce probability a map, which is then followed by polygon simplification. However, both approaches are either hard to train or contain many steps before the final output.
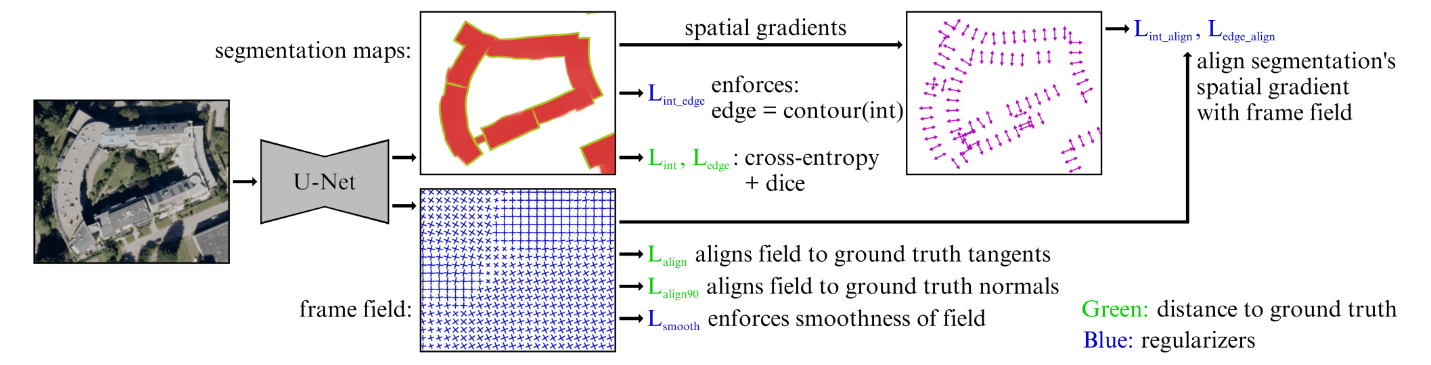
For an end-to-end method that is easy to optimize, the authors propose to build on the semantic segmentation methods, where in addition to predicting a segmentation maps corresponding to the buildings in the image, they also task the model with predicting a frame field as a geometric prior to constrain the segmentation maps to have sharpe corners.
Other papers to check out
- VIP-DeepLab: Learning Visual Perception With Depth-Aware Video Panoptic Segmentation
- Exemplar-Based Open-Set Panoptic Segmentation Network
- The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth
- Robust Consistent Video Depth Estimation
- Scene Essence
- Semantic Segmentation With Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization
- Repurposing GANs for One-Shot Semantic Part Segmentation
- Deep Occlusion-Aware Instance Segmentation With Overlapping BiLayers
- Information-Theoretic Segmentation by Inpainting Error Maximization
- Single Image Depth Prediction With Wavelet Decomposition
- Learning to Recover 3D Scene Shape from a Single Image
Representation & Adversarial Learning
Exploring Simple Siamese Representation Learning (Paper)
In the recent contrastive learning methods used for learning useful visual representation in an unsupervised manner, a model is trained to map similar input images close by in the embedding space. Such methods, such MoCo, SimCLR, or BYOL, add some additional conditions to the similarity maximization objective to avoid collapsing solutions, such as negative sample pairs, large batches, or momentum encoders.

This paper investigates the usage of SimSiam, a simple Siamese based setup where such conditions are not necessary. Such an architecture consists of an encoder and a projector/predictor, which are then trained to maximize the similarity between a two given features (one after projection and one without) corresponding to two augmented version of an input image with a stop gradient operator applied to the second non projected output. The obtained results show that this simple approach gives are similar to other more elaborate approaches, indicating that the Siamese architecture may be an essential reason for the common success of the other related contrastive methods, see section 5 for more details.
Where and What? Examining Interpretable Disentangled Representations (Paper)
In disentangled representation learning, the objective is produce a representation of an input, where each dimension captures variations with a semantic meaning. One of the main limitations of existing work is their inability to differentiate between entangled and disentangled representations in the solution pool.
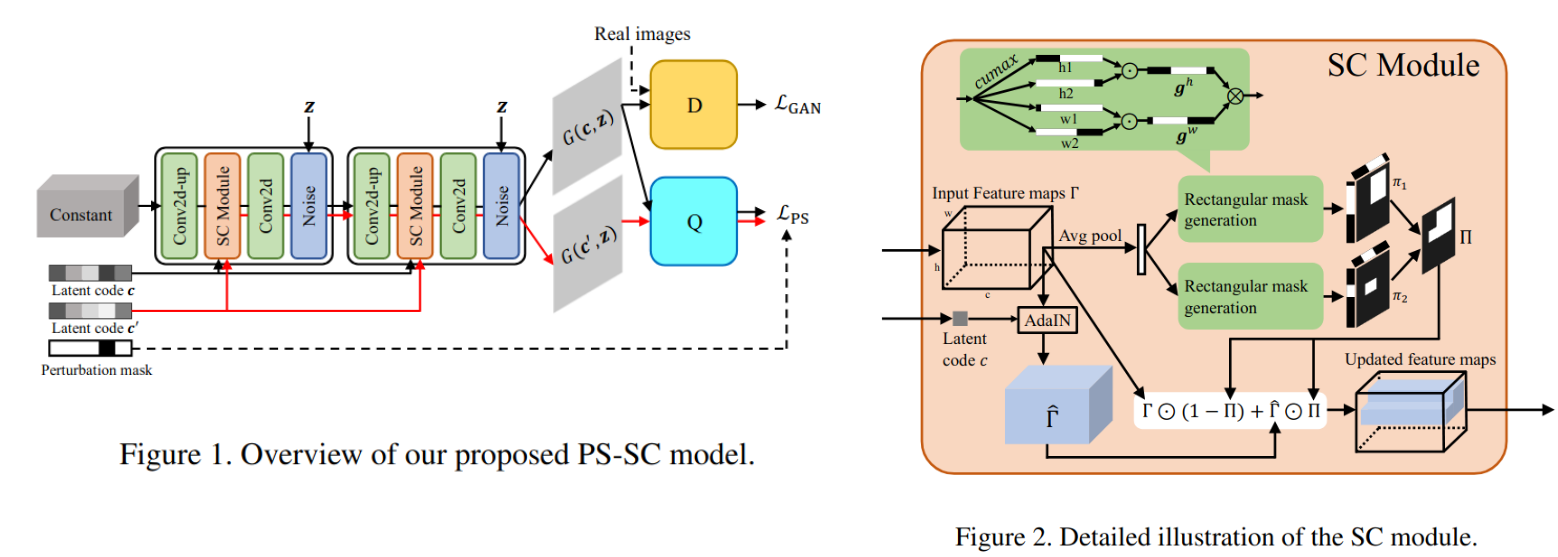
To solve this non-uniqueness problem, the paper defines disentanglement from three perspectives: informativeness, independence, and interpretability. By adding interpretability condition to the produced representations, we force the model to only produce disentangled representations that do correspond to human-defined concepts. Now, the question becomes how can we enforce such an interpretability constraint in the representations without supervision?. To solve this, the authors propose to exploit two hypotheses about interpretability to learn disentangled representations. The first one is Spatial Constriction (SC): a representation is usually interpretable if we can consistently tell where the controlled variations are in an image. The second hypothesis is Perceptual Simplicity: an interpretable code usually corresponds to a concept consisting of perceptually simple variations.
Based on these two hypothesis, a new model is introduced, where the Spatial Constriction is enforced with a SC module that restricts the impact of each latent code to specific areas on feature maps during generation. As for Perceptual Simplicity, the model is trained with a loss that encourages the model to embed simple data variations along each latent dimension.
Audio-Visual Instance Discrimination with Cross-Modal Agreement (Paper)
The paper presents a for cross-modal discrimination for self-supervised learning in order to learn audio-visual representations from video and audio. The proposed contrastive learning frame-work consists of contrasting video representations against multiple audios representations at once (and vice versa), thus the cross-modal nature of the method.
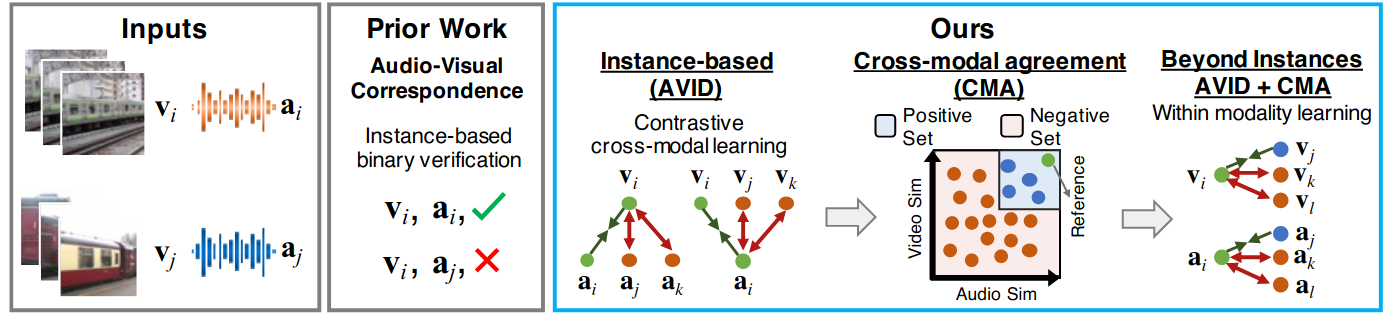
The proposed approach learns both a cross-modal similarity metric by grouping video and audio instances that co-occur over multiple instances, in addition to optimizing for visual similarity rather than just cross-modal similarity.
UP-DETR: Unsupervised Pre-Training for Object Detection With Transformers (Paper)
While DETR proposed a simple end-to-end object detector, thus removing all hand-designed components, it still comes with some training and optimization challenges, requiring large-scale training data and long training times (up to 500 epochs). UP-DETR proposes a new unsupervised pre-training tasks in order to reduce the amount of training time and data required, where DETR is first pre-trained on a pretext task designed specifically for object detection as a desired down-stream task, then fine-tunned for object detection.
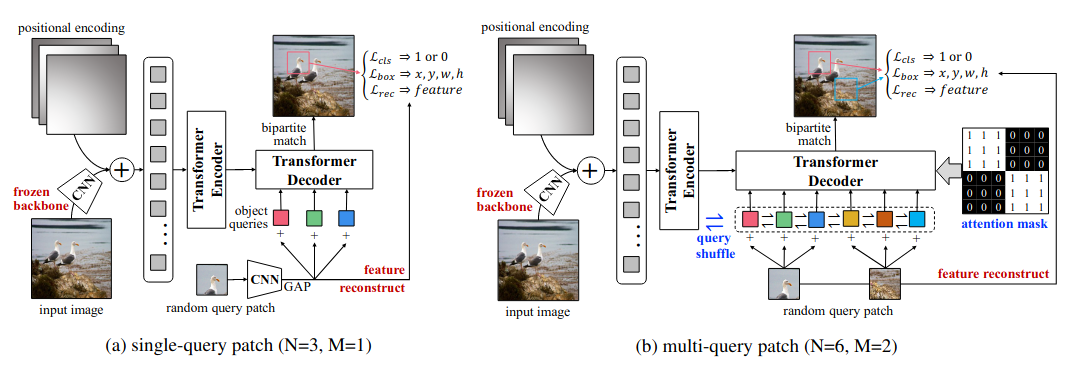
Unsupervised Pre-training DETR (UP-DETR) defines random query patch detection as a pretext task to pre-train DETR in a self-supervised manner. For this task, a set of patches are first cropped from the input image at random, the model is then trained to predict the bounding boxes of these patches. The objective of this pre-training stage is to equip the model with better localization while maintaining its classification features. So to avoid suppressing the learned classification features of the pre-trained backbone, UP-DETR freezes the backbone and adds a patch feature reconstruction loss. Additionally, in order to specify the query patch the model needs to detect, the CNN features of the patch itself are added to the object queries before feeding them to the decoder. For multi-patch detection, the patches are grouped into sets of patches and each set is assigned to a given object query, and the attention aggregation is applied with a masking operation so that each prediction is not dependent on the rest (see section 3.2).
Fast End-to-End Learning on Protein Surfaces (Paper)
Chemically, proteins are composed of a sequence of amino acids which determines the structure (called fold) of the protein, and this structure in turn determines the function the protein will have. The task of either structure prediction from a sequence of amino acids (what AlphaFold does) or the protein design from its structure, are both major unsolved problems in structural biology. Another challenging problem, the task of interest in this paper, is the study of the interactions of a given molecule with other molecules given their composition in order to identify interaction patterns on protein surfaces.
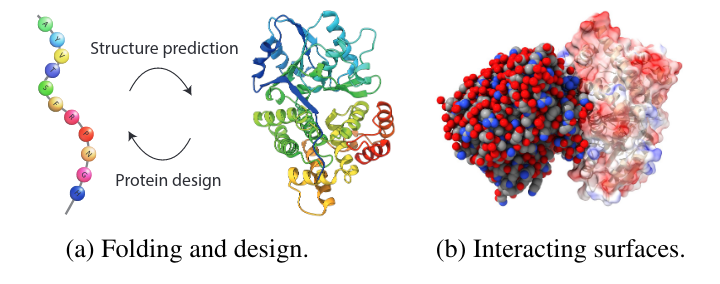
In this context, the paper proposes dMaSIF (differentiable molecular surface interaction fingerprinting), a new and computationally efficient deep learning approach that operates directly on the large set of atoms that compose the protein. It first generates a point cloud representation for the protein surface, learns task-specific geometric and chemical features on the surface point cloud, and finally, applies a new convolutional operator that approximates geodesic coordinates in the tangent space (please see the paper since I’m way over my head here).
Natural Adversarial Examples (Paper)
ImageNet test examples tend to be simple, clear, close-up images, so the current test set may be too easy and may not represent harder images encountered in the real world, and a large capacity model can leverage spurious cues or shortcuts to solve the ImageNet classification problem. To counteract this, the paper proposes two hard ImageNet test sets: ImageNet-A and ImageNet-O of natural adversarial examples with adversarial filtration.
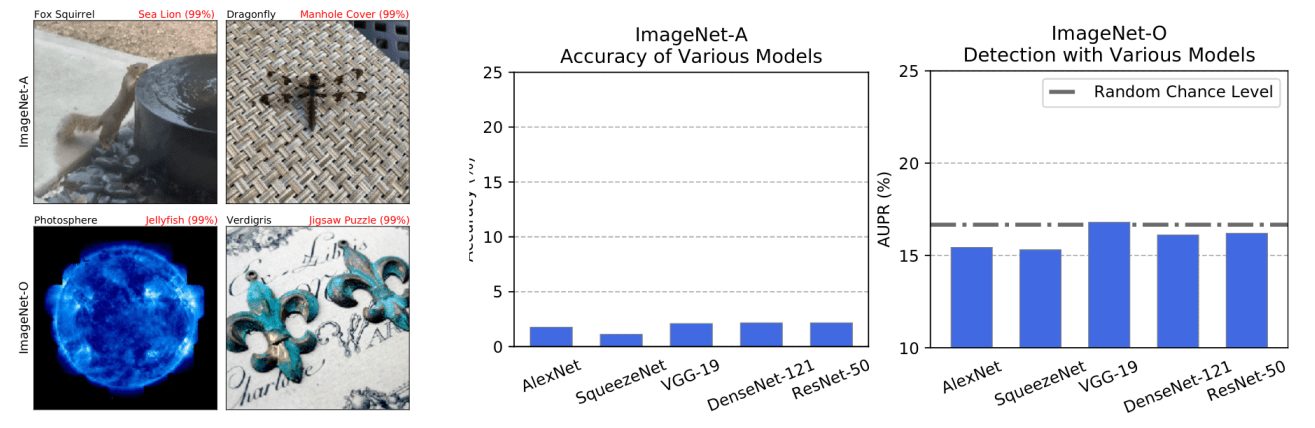
ImageNet-A consists of real-world adversarially filtered images that fool current ImageNet classifiers. Starting from a large set of images related to an ImageNet class, adversarially filtered examples are found by removing the samples that are correctly classified by ResNet-50 trained on ImageNet. ImageNet-O on the other hand in is a dataset of adversarially filtered examples for ImageNet out-of-distribution detectors. Starting from ImageNet-22K, first, all of the examples that belong to ImageNet-1K classes are removed. Then, using a ResNet-50, the only maintained examples are the ones that were classified by the model into ImageNet-1K classes with high confidence.
- Spatiotemporal Contrastive Video Representation Learning
- Adversarially Adaptive Normalization for Single Domain Generalization
- Self-Supervised Geometric Perception
- CutPaste: Self-Supervised Learning for Anomaly Detection and Localization
- Taskology: Utilizing Task Relations at Scale
- MOS: Towards Scaling Out-of-Distribution Detection for Large Semantic Space
Transfer, Low-shot, Semi & Unsupervised Learning
DatasetGAN: Efficient Labeled Data Factory With Minimal Human Effort (Paper)
DatasetGAN is a method that generates massive datasets of high-quality semantically segmented images with minimal human effort. Based on the observation that GaNs are capable of acquiring rich semantic knowledge in order to render diverse and realistic examples of objects, DatasetGAN exploits the feature space of a trained GAN and trains a shallow decoder to produce a pixel-level labeling, where such a decoder is first trained on a very small number of labeled examples, and can then be used to labeled an infinite amount of synthetic images. The generated dataset can be used to train a model in an semi-supervised manner on the synthetic dataset, which can then be tested on real world images.

The architecture of DatasetGAN consist of two models, a StyleGAN that generates synthetic image, in addition to Style-Interpreter in the form of an ensemble of three-layer MLP classifiers, where each classifier takes as inputs feature maps from StyleGAN (outputs of AdaIN layers), upsamples them to the image resolutions, and predicts the pixel-level labels. The final prediction is the aggregation of the predictions of all of the MLP classifiers, which then trained with a small number of finely annotated examples and used for labeling the synthetic images.
Ranking Neural Checkpoints (Paper)
During a given deep learning experiment, it is common practice to collect many checkpoint, which are different versions of the final model at different training iterations. This paper is concerned with ranking such checkpoints to find the models that best transfers to the downstream task of interest.
More specifically, given a number of pretrained neural nets, called checkpoints \(\mathcal{C}\). The objective is to find the best checkpoint over a distribution of downstream tasks \(\mathcal{T}\). Each task consists of training and testing sets, and an evaluation procedure \(\mathbf{G}\) that adjusts the pretrained model by adding the task specific head, finetunes the model on the training set with a hyperparameter sweep under a given computation contraint, and retuns a performance measure \(\mathbf{R}\). The objective of the paper is to find the best measure \(\mathcal{M}\) to correctly rank the checkpoints.
\[\mathbf{R}^{*} \leftarrow \underset{\mathbf{R} \in \mathcal{R}}{\arg \max } \mathbb{E}_{t \sim \mathcal{T}} \mathcal{M}\left(\mathbf{R}_{t}, \mathbf{G}_{t}\right)\]The paper proposes a measure called NLEEP, an extention of LEEP that evaluates the degree of transferability of the learned representations from source to target data without training. LEEP consists of computing the empirical conditional distribution of target labels given dummy source labels to measure the degree of transferability. NLEEP simply replaces the softmax classifier used for generating the dummy source labels with a Gaussian mixture model for more reliable class assignments. This way, we can evaluate the checkpoints on downstrem tasks while reducing cost of the evaluation procedure since LEEP does not require fine-tuning on the target data.
Other papers to check out
- MeanShift++: Extremely Fast Mode-Seeking With Applications to Segmentation and Object Tracking
- Meta Pseudo Labels
- Adaptive Prototype Learning and Allocation for Few-Shot Segmentation
- Student-Teacher Learning From Clean Inputs to Noisy Inputs
- Learning Graph Embeddings for Compositional Zero-Shot Learning
Computational Photography
Real-Time High-Resolution Background Matting (Paper)

While many tools now provide background replacement functionality, they often yield artifacts at the boundaries, particularly in areas where there is fine detail like hair or glasses. On the other hand, the traditional image matting methods provide much higher quality results, but do not run in real-time, at high resolutions, and frequently require manual input.
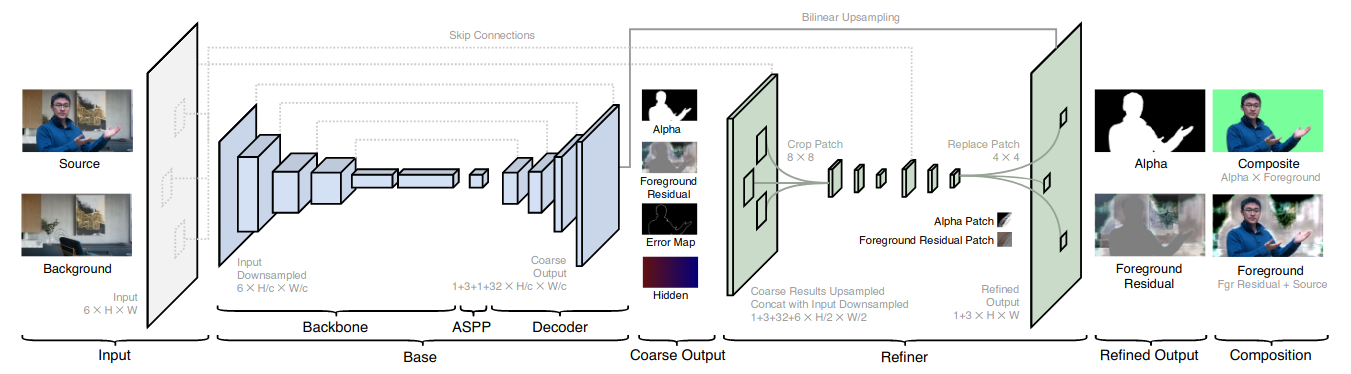
This paper proposes a real-time and high-resolution background matting method capable of processing 4K (3840x2160) images at 30fps and HD (1920x1080) images at 60fps. To acheive this, the model needs to be trained on large volumes of images with high-quality alpha mattes to generalize. To this end, the paper introduces two datasets with high-resolution alpha mattes and foreground layers extracted with chroma-key software. The model is then trained on these datases to learn strong priors, then fine-tunned on public dataset to learn fine-grained details. As for the network design, the model contains two processing paths; a base network that predicts the alpha matte and foreground layer at lower resolution, along with an error prediction map which specifies areas that may need high-resolution refinement. Based on this maps, a refinement network then takes the low-resolution result and the original image to generate high-resolution output, but only at select regions for efficency.
Im2Vec: Synthesizing Vector Graphics without Vector Supervision (Paper)
Despite the large amount of generative methods for images, there a limited amount of approaches that operate directly on vector graphics and require direct supervison. To solve this, the paper proposes Im2Vec, a new neural network that generates complex vector graphics with varying topologies, and only requires indirect supervision from readily-available training imges with no vector counterparts.
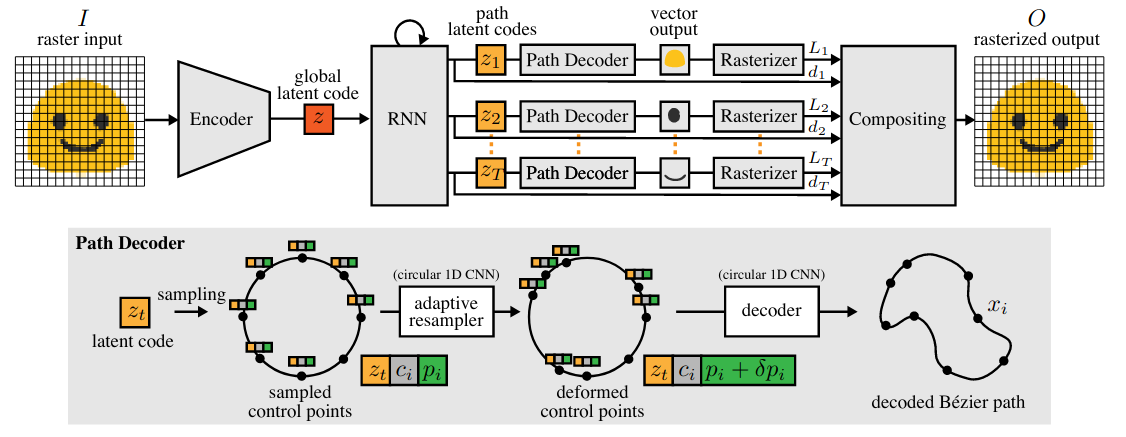
Im2Vec consists of a standard encode-decoder architecture. Given an input image, the encoder maps it into a latent variable, which is then decoded into a vector graphic structure. The decoder on the other hand is designed so that it can generate complex graphics (see section 3 of the paper for more details).
Other papers to check out
- Passive Inter-Photon Imaging
- Event-Based Synthetic Aperture Imaging With a Hybrid Network
- GAN Prior Embedded Network for Blind Face Restoration in the Wild
- Mask Guided Matting via Progressive Refinement Network
Other
Biometrics, Face, Gesture and Body Pose
- SMPLicit: Topology-Aware Generative Model for Clothed People
- On Self-Contact and Human Pose
- Body2Hands: Learning To Infer 3D Hands From Conversational Gesture Body Dynamics
- PoseAug: A Differentiable Pose Augmentation Framework for 3D Human Pose Estimation
- OSTeC: One-Shot Texture Completion
- SCANimate: Weakly Supervised Learning of Skinned Clothed Avatar Networks
- HOTR: End-to-End Human-Object Interaction Detection with Transformers
- Birds of a Feather: Capturing Avian Shape Models From Images
Vision & Language
- Less is More: ClipBERT for Video-and-Language Learning via Sparse Sampling
- Multimodal Contrastive Training for Visual Representation Learning
- ArtEmis: Affective Language for Visual Art
- VirTex: Learning Visual Representations From Textual Annotations
- Learning by Planning: Language-Guided Global Image Editing
Datasets
- Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
- Enriching ImageNet With Human Similarity Judgments and Psychological Embeddings
- Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets
- SAIL-VOS 3D: A Synthetic Dataset and Baselines for Object Detection and 3D Mesh Reconstruction From Video Data
Explainable AI & Privacy
- Privacy-Preserving Image Features via Adversarial Affine Subspace Embeddings
- Transformer Interpretability Beyond Attention Visualization
- Black-box Explanation of Object Detectors via Saliency Maps
Video Analysis and Understanding
- Guided Interactive Video Object Segmentation Using Reliability-Based Attention Maps
- Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
- Omnimatte: Associating Objects and Their Effects in Video
- SSTVOS: Sparse Spatiotemporal Transformers for Video Object Segmentation